

通用多层 JSON 制作工具:从 Excel 到结构化数据的优雅转身
在数据处理的日常工作中,我们经常需要将 Excel 表格中的扁平化数据转换为层级分明的 JSON 格式,以便于后续的系统对接或数据分析。本文将详细介绍一款基于 Python PyQt5 开发的“通用多层 JSON 制作工具”,它不仅支持灵活的列映射,还引入了强大的正则表达式匹配功能,让数据转换变得前所未有的简单和高效。
Githun链接:Excel多层json制作工具
Githun链接:Excel多层json制作工具
Githun链接:Excel多层json制作工具
🛠️ 工具背景与痛点
在物流、电商或财务对账等场景中,我们经常遇到这样的 Excel 报表:
| 运单号码 | 增值费用类型 | 应付金额 |
|---|---|---|
| SF1001 | 快递运费 | 10.00 |
| SF1001 | 包装服务 | 2.00 |
| SF1002 | 异地转寄 | 12.00 |
| SF1003 | 运费 | 15.00 |
我们的目标通常是将其转换为如下结构的 JSON:
{
"运费类": {
"SF1001": 10.00,
"SF1003": 15.00
},
"增值服务": {
"SF1001": 2.00
},
"异常费用": {
"SF1002": 12.00
}
}
痛点在于:
- 分类规则复杂:Excel 中的“增值费用类型”描述可能不统一(如“快递运费”和“运费”其实是一类)。
- 结构需求多变:有时需要两层嵌套,有时需要三层;有时需要覆盖旧值,有时需要累加金额。
- 硬编码维护难:如果每次规则变化都要修改代码,效率极低。
✨ 核心功能亮点
这款工具正是为了解决上述问题而生,它具备以下核心特性:
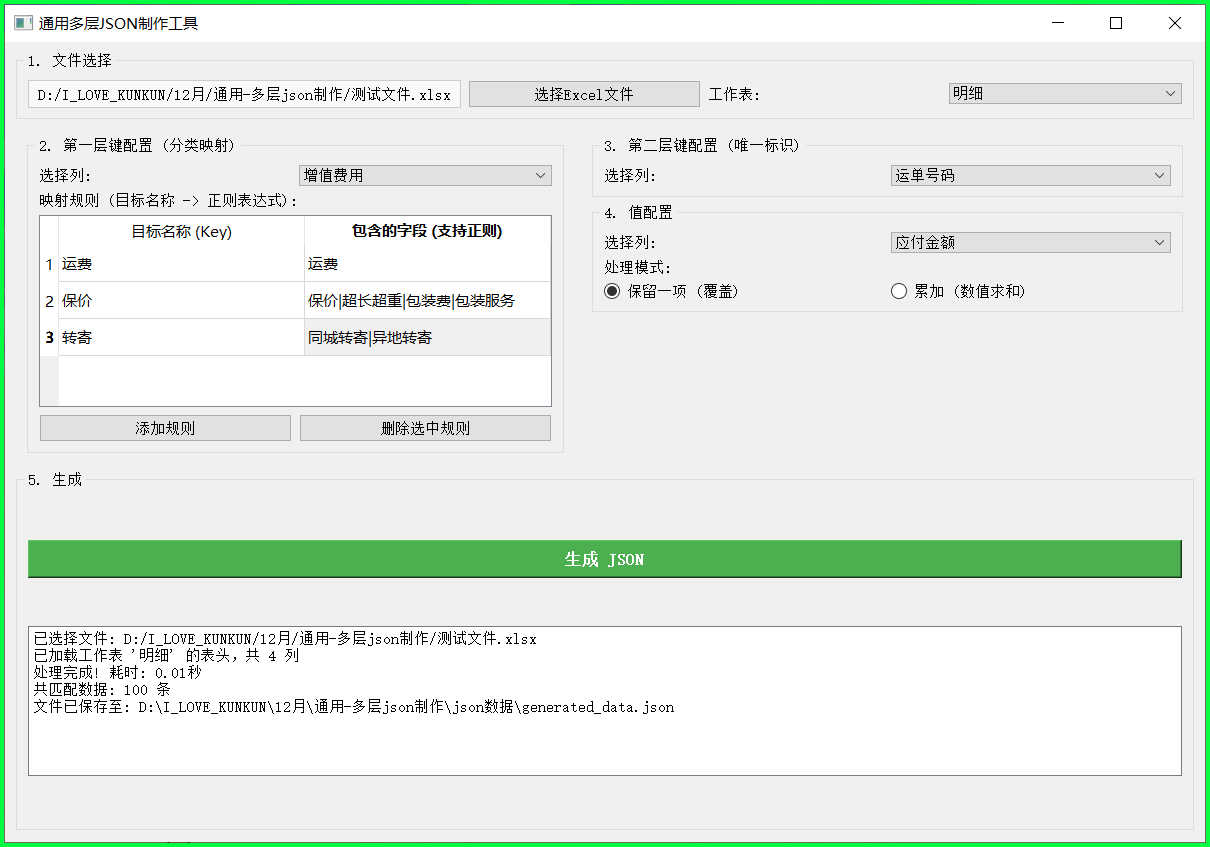
1. 🎨 图形化操作界面 (GUI)
告别枯燥的命令行,采用 PyQt5 构建的现代化界面,操作直观。
- 文件一键加载:支持
.xlsx和.xls格式,自动读取所有工作表。 - 智能列名识别:自动读取表头,供用户通过下拉框选择关键列。
2. 🧩 灵活的多层键值映射
工具采用了经典的“Key-Key-Value”三层映射逻辑:
- 第一层键 (Category):通过规则将某一列的值映射为大的分类(如“运费”、“包装费”)。
- 第二层键 (ID):通常是唯一标识,如“运单号码”。
- 值 (Value):具体的数据,如“应付金额”。
3. 🚀 强大的正则匹配 (Regex) 🔥
这是本工具最大的杀手锏!在配置第一层键的映射规则时,全面支持正则表达式。
- 模糊匹配:输入
^SF.*可以匹配所有以 SF 开头的字符。 - 多词匹配:输入
快递|运费可以同时匹配“快递运费”、“标准运费”、“运费补收”等所有包含关键词的项。 - 包含匹配:输入
包装即可一网打尽“包装费”、“包装服务”、“木架包装”等。
4. 📊 智能数值处理
针对“值”的处理,提供两种模式:
- 保留一项 (覆盖):适用于文本信息或只取最新值的场景。
- 累加 (数值求和):适用于金额统计。例如,同一个运单有多笔“运费”记录时,工具会自动将其金额相加,并保留两位小数。
📖 使用指南
第一步:准备数据
确保你的 Excel 文件第一行为表头。例如:
测试文件.xlsx
| 运单号码 | 增值费用 | 应付金额 |
|---|---|---|
| SF1001 | 快递运费 | 10.00 |
| ... | ... | ... |
第二步:启动工具
运行脚本:
python make_json.py
第三步:配置规则
- 选择文件:加载你的 Excel 文件。
- 第一层键配置:
- 选择列:
增值费用 - 添加规则:
- 目标名称:
基础运费-> 匹配正则:快递|运费 - 目标名称:
包装费-> 匹配正则:包装
- 目标名称:
- 选择列:
- 第二层键配置:
- 选择列:
运单号码
- 选择列:
- 值配置:
- 选择列:
应付金额 - 模式:选择
累加
- 选择列:
第四步:一键生成
点击“生成 JSON”,工具会迅速处理数据,并在根目录下的 json数据 文件夹中生成 generated_data.json。
💻 技术实现细节
核心依赖
- PyQt5: 用于构建跨平台的桌面应用程序界面。
- python-calamine: 一个基于 Rust 的高性能 Excel 读取库,比传统的 pandas/openpyxl 读取速度更快,尤其适合处理大文件。
- re: Python 内置的正则表达式模块,提供强大的文本匹配能力。
关键代码片段
处理数据的核心逻辑展示了如何利用正则进行动态分类:
# 遍历每一行数据
for row in rows:
# ... 获取原始数据 ...
# 1. 匹配第一层键 (正则匹配)
target_key = None
check_val = str(raw_first)
for target, regex in mappings:
if regex.search(check_val): # 使用预编译的正则对象进行搜索
target_key = target
break
if not target_key: continue # 没匹配到规则则跳过
# 2. 处理值的累加或覆盖
if is_accumulate:
current = result_data[target_key].get(second_key, 0.0)
result_data[target_key][second_key] = current + val
else:
result_data[target_key][second_key] = val
📝 总结
这款“通用多层 JSON 制作工具”展示了 Python 在办公自动化领域的强大潜力。通过结合 GUI 交互与正则处理逻辑,它将原本复杂的硬编码任务变成了只需点击几下鼠标的简单配置。
无论你是需要处理财务报表的会计,还是需要清洗数据的工程师,这款小工具都能成为你提升效率的得力助手。
生成的 JSON 数据默认保存在工具运行的根目录下,方便查找和使用。
通用多层 JSON 制作工具:从 Excel 到结构化数据的优雅转身
在数据处理的日常工作中,我们经常需要将 Excel 表格中的扁平化数据转换为层级分明的 JSON 格式,以便于后续的系统对接或数据分析。本文将详细介绍一款基于 Python PyQt5 开发的“通用多层 JSON 制作工具”,它不仅支持灵活的列映射,还引入了强大的正则表达式匹配功能,让数据转换变得前所未有的简单和高效。
🛠️ 工具背景与痛点
在物流、电商或财务对账等场景中,我们经常遇到这样的 Excel 报表:
| 运单号码 | 增值费用类型 | 应付金额 |
|---|---|---|
| SF1001 | 快递运费 | 10.00 |
| SF1001 | 包装服务 | 2.00 |
| SF1002 | 异地转寄 | 12.00 |
| SF1003 | 运费 | 15.00 |
我们的目标通常是将其转换为如下结构的 JSON:
{
"运费类": {
"SF1001": 10.00,
"SF1003": 15.00
},
"增值服务": {
"SF1001": 2.00
},
"异常费用": {
"SF1002": 12.00
}
}
痛点在于:
- 分类规则复杂:Excel 中的“增值费用类型”描述可能不统一(如“快递运费”和“运费”其实是一类)。
- 结构需求多变:有时需要两层嵌套,有时需要三层;有时需要覆盖旧值,有时需要累加金额。
- 硬编码维护难:如果每次规则变化都要修改代码,效率极低。
✨ 核心功能亮点
这款工具正是为了解决上述问题而生,它具备以下核心特性:
1. 🎨 图形化操作界面 (GUI)
告别枯燥的命令行,采用 PyQt5 构建的现代化界面,操作直观。
- 文件一键加载:支持
.xlsx和.xls格式,自动读取所有工作表。 - 智能列名识别:自动读取表头,供用户通过下拉框选择关键列。
2. 🧩 灵活的多层键值映射
工具采用了经典的“Key-Key-Value”三层映射逻辑:
- 第一层键 (Category):通过规则将某一列的值映射为大的分类(如“运费”、“包装费”)。
- 第二层键 (ID):通常是唯一标识,如“运单号码”。
- 值 (Value):具体的数据,如“应付金额”。
3. 🚀 强大的正则匹配 (Regex) 🔥
这是本工具最大的杀手锏!在配置第一层键的映射规则时,全面支持正则表达式。
- 模糊匹配:输入
^SF.*可以匹配所有以 SF 开头的字符。 - 多词匹配:输入
快递|运费可以同时匹配“快递运费”、“标准运费”、“运费补收”等所有包含关键词的项。 - 包含匹配:输入
包装即可一网打尽“包装费”、“包装服务”、“木架包装”等。
4. 📊 智能数值处理
针对“值”的处理,提供两种模式:
- 保留一项 (覆盖):适用于文本信息或只取最新值的场景。
- 累加 (数值求和):适用于金额统计。例如,同一个运单有多笔“运费”记录时,工具会自动将其金额相加,并保留两位小数。
📖 使用指南
第一步:准备数据
确保你的 Excel 文件第一行为表头。例如:
测试文件.xlsx
| 运单号码 | 增值费用 | 应付金额 |
|---|---|---|
| SF1001 | 快递运费 | 10.00 |
| ... | ... | ... |
第二步:启动工具
运行脚本:
python make_json.py
第三步:配置规则
- 选择文件:加载你的 Excel 文件。
- 第一层键配置:
- 选择列:
增值费用 - 添加规则:
- 目标名称:
基础运费-> 匹配正则:快递|运费 - 目标名称:
包装费-> 匹配正则:包装
- 目标名称:
- 选择列:
- 第二层键配置:
- 选择列:
运单号码
- 选择列:
- 值配置:
- 选择列:
应付金额 - 模式:选择
累加
- 选择列:
第四步:一键生成
点击“生成 JSON”,工具会迅速处理数据,并在根目录下的 json数据 文件夹中生成 generated_data.json。
💻 技术实现细节
核心依赖
- PyQt5: 用于构建跨平台的桌面应用程序界面。
- python-calamine: 一个基于 Rust 的高性能 Excel 读取库,比传统的 pandas/openpyxl 读取速度更快,尤其适合处理大文件。
- re: Python 内置的正则表达式模块,提供强大的文本匹配能力。
关键代码片段
处理数据的核心逻辑展示了如何利用正则进行动态分类:
# 遍历每一行数据
for row in rows:
# ... 获取原始数据 ...
# 1. 匹配第一层键 (正则匹配)
target_key = None
check_val = str(raw_first)
for target, regex in mappings:
if regex.search(check_val): # 使用预编译的正则对象进行搜索
target_key = target
break
if not target_key: continue # 没匹配到规则则跳过
# 2. 处理值的累加或覆盖
if is_accumulate:
current = result_data[target_key].get(second_key, 0.0)
result_data[target_key][second_key] = current + val
else:
result_data[target_key][second_key] = val
📝 总结
这款“通用多层 JSON 制作工具”展示了 Python 在办公自动化领域的强大潜力。通过结合 GUI 交互与正则处理逻辑,它将原本复杂的硬编码任务变成了只需点击几下鼠标的简单配置。
无论你是需要处理财务报表的会计,还是需要清洗数据的工程师,这款小工具都能成为你提升效率的得力助手。
生成的 JSON 数据默认保存在工具运行的根目录下,方便查找和使用。