

Python爬虫实战:手把手教你抓取彼岸桌面高清美女壁纸
在学习Python爬虫的过程中,实战是最好的老师。今天我们将通过一个具体的案例——抓取 彼岸桌面 (netbian.com) 的美女分类壁纸,来学习如何使用 requests 和 re(正则表达式)模块编写一个简单的图片爬虫。
彼岸桌面是一个质量非常高的壁纸网站,结构清晰,非常适合作为爬虫新手的练习对象。
1. 准备工作
在开始编写代码之前,我们需要确保安装了必要的Python库。本次实战主要使用 requests 发送网络请求,使用 re 进行数据解析。
如果你的环境中还没有安装 requests,可以通过以下命令安装:
pip install requests
2. 爬虫思路分析
编写爬虫通常遵循以下步骤:
- 分析目标网站:确定要抓取的URL规律,查看网页源代码结构。
- 目标URL:
http://www.netbian.com/meinv/ - 编码格式:该网站使用
GBK编码,解码时需要注意。 - 反爬策略:该网站有基础的反爬虫机制,必须设置
User-Agent,最好也带上Referer。
- 目标URL:
- 获取列表页内容:访问分类首页,获取包含壁纸详情页链接的HTML。
- 提取详情页链接:从列表页中解析出每一个壁纸的详情页面URL(例如
/desk/12345.htm)。 - 进入详情页:遍历每一个详情页,获取大图的真实下载地址。
- 下载图片:请求大图地址并保存到本地。
- 翻页处理:处理多页抓取逻辑(
index_2.htm,index_3.htm等)。
3. 代码实现与详解
下面我们将逐步实现这个爬虫。
3.1 引入库与配置
首先引入必要的库,并设置全局配置。
import re
import requests
import os
import time
import random
# 配置部分
BASE_URL = "http://www.netbian.com"
START_URL = "http://www.netbian.com/meinv/"
SAVE_DIR = os.path.join(os.getcwd(), "images_netbian") # 图片保存路径
# 设置请求头,必须带上 User-Agent,否则会被拦截
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'http://www.netbian.com/',
}
3.2 获取网页源码
我们需要一个通用的函数来获取网页内容,并处理编码和异常。
def get_html(url, retries=3):
"""获取网页源码,包含重试机制"""
for i in range(retries):
try:
response = requests.get(url, headers=HEADERS, timeout=10)
# 关键点:彼岸桌面使用 gbk 编码
response.encoding = "gbk"
if response.status_code == 200:
return response.text
print(f"请求失败 (状态码 {response.status_code}): {url}")
except requests.RequestException as e:
print(f"请求异常 (尝试 {i+1}/{retries}): {e}")
time.sleep(random.uniform(1, 3))
return None
3.3 提取详情页链接
列表页中包含了许多缩略图和指向详情页的链接。我们需要提取出形如 /desk/xxxxx.htm 的链接。
def get_detail_links(html):
"""从列表页提取详情页链接"""
if not html:
return []
# 正则匹配 href="/desk/..."
links = re.findall(r'href="(/desk/\d+\.htm)"', html)
# 去重
unique_links = list(set(links))
print(f"本页发现 {len(unique_links)} 个壁纸链接")
return unique_links
3.4 核心逻辑:遍历与下载
这是爬虫的主循环。我们先遍历列表页,再进入详情页抓取大图。
def main():
# 创建保存目录
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
global_count = 0
# 爬取前 3 页 (range(1, 4) 表示 1, 2, 3)
for page in range(1, 4):
if page == 1:
url = START_URL
else:
# 翻页规律: index_2.htm, index_3.htm
url = f"{START_URL}index_{page}.htm"
print(f"\n>>> 正在访问列表页: {url}")
list_html = get_html(url)
if not list_html:
continue
detail_links = get_detail_links(list_html)
for link in detail_links:
detail_url = BASE_URL + link
detail_html = get_html(detail_url)
if not detail_html:
continue
# 提取大图链接
# 策略:先定位 <div class="pic"> 区域,再提取里面的 img src
pic_div_match = re.search(r'<div class="pic">.*?</div>', detail_html, re.S)
img_url = ""
if pic_div_match:
pic_content = pic_div_match.group()
# 匹配 http://img.netbian.com/file/...jpg
img_match = re.search(r'src="(http://img\.netbian\.com/file/[^"]+\.jpg)"', pic_content)
if img_match:
img_url = img_match.group(1)
if img_url:
global_count += 1
print(f"正在下载第 {global_count} 张: {img_url}")
try:
img_data = requests.get(img_url, headers=HEADERS, timeout=15).content
with open(os.path.join(SAVE_DIR, f"{global_count}.jpg"), "wb") as f:
f.write(img_data)
except Exception as e:
print(f"下载失败: {e}")
# 礼貌性延时
time.sleep(random.uniform(0.5, 1.5))
if __name__ == "__main__":
main()
4. 关键技术点总结
- 编码处理:很多中文老站使用
GBK编码,如果直接使用默认编码会出现乱码,必须设置response.encoding = 'gbk'。 - 反爬虫:
- User-Agent:必须伪装成浏览器。
- Referer:部分图片服务器会检查引用页,防止盗链。
- 延时:使用
time.sleep控制请求频率,既是为了防封,也是为了减轻对方服务器压力。
- 正则提取技巧:
- 先定位大块区域(如
<div class="pic">...</div>),再在区域内精确匹配,可以避免匹配到侧边栏或推荐位的无关图片。
- 先定位大块区域(如
完整代码
import re
import requests
import os
import time
import random
# 配置部分
BASE_URL = "http://www.netbian.com"
START_URL = "http://www.netbian.com/meinv/"
SAVE_DIR = os.path.join(os.getcwd(), "images_netbian")
# 必须带上 User-Agent,否则彼岸桌面会拦截
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'http://www.netbian.com/',
}
def setup_directory(directory):
"""确保保存目录存在"""
if not os.path.exists(directory):
print(f"正在创建保存目录: {directory}")
os.makedirs(directory)
def get_html(url, retries=3):
"""获取网页源码,包含重试机制"""
for i in range(retries):
try:
response = requests.get(url, headers=HEADERS, timeout=10)
# 彼岸桌面通常使用 gbk 编码
response.encoding = "gbk"
if response.status_code == 200:
return response.text
print(f"请求失败 (状态码 {response.status_code}): {url}")
except requests.RequestException as e:
print(f"请求异常 (尝试 {i+1}/{retries}): {e}")
time.sleep(random.uniform(1, 3))
return None
def get_detail_links(html):
"""从列表页提取详情页链接"""
if not html:
return []
# 提取形如 /desk/12345.htm 的链接
# 注意:彼岸桌面的详情页链接通常是 /desk/数字.htm
links = re.findall(r'href="(/desk/\d+\.htm)"', html)
# 去重
unique_links = []
for link in links:
if link not in unique_links:
unique_links.append(link)
print(f"本页发现 {len(unique_links)} 个壁纸链接")
return unique_links
def download_image(img_url, count):
"""下载单张图片"""
try:
# 获取图片内容
img_response = requests.get(img_url, headers=HEADERS, timeout=15)
if img_response.status_code != 200:
print(f"图片下载失败: {img_url}")
return False
file_path = os.path.join(SAVE_DIR, f"{count}.jpg")
with open(file_path, "wb") as f:
f.write(img_response.content)
print(f"[成功] 保存第 {count} 张图片: {file_path}")
return True
except Exception as e:
print(f"[失败] 下载图片出错 {img_url}: {e}")
return False
def main():
setup_directory(SAVE_DIR)
global_count = 0
# 爬取前 3 页 (可以根据需要修改 range)
for page in range(1, 4):
if page == 1:
url = START_URL
else:
url = f"{START_URL}index_{page}.htm"
print(f"\n>>> 正在访问列表页: {url}")
list_html = get_html(url)
if not list_html:
continue
detail_links = get_detail_links(list_html)
for link in detail_links:
detail_url = BASE_URL + link
# print(f" 正在处理详情页: {detail_url}")
detail_html = get_html(detail_url)
if not detail_html:
continue
# 提取大图链接
# 结构通常是: <div class="pic">...<img src="http://img.netbian.com/..." ...>
# 我们先定位到 pic div,再提取 img
# 简化正则: 寻找 class="pic" 附近的 img src
# 或者直接匹配特定域名的图片,彼岸大图通常在 img.netbian.com/file/...
# 策略:先尝试匹配 <div class="pic"> 区域,确保不抓到缩略图
pic_div_match = re.search(r'<div class="pic">.*?</div>', detail_html, re.S)
img_url = ""
if pic_div_match:
pic_content = pic_div_match.group()
img_match = re.search(r'src="(http://img\.netbian\.com/file/[^"]+\.jpg)"', pic_content)
if img_match:
img_url = img_match.group(1)
if img_url:
global_count += 1
download_image(img_url, global_count)
# 随机延时,防止对服务器造成过大压力
time.sleep(random.uniform(0.5, 1.5))
else:
print(f" 未在页面 {detail_url} 找到大图")
print(f"\n所有任务完成,共下载 {global_count} 张图片。")
if __name__ == "__main__":
main()
5. 总结
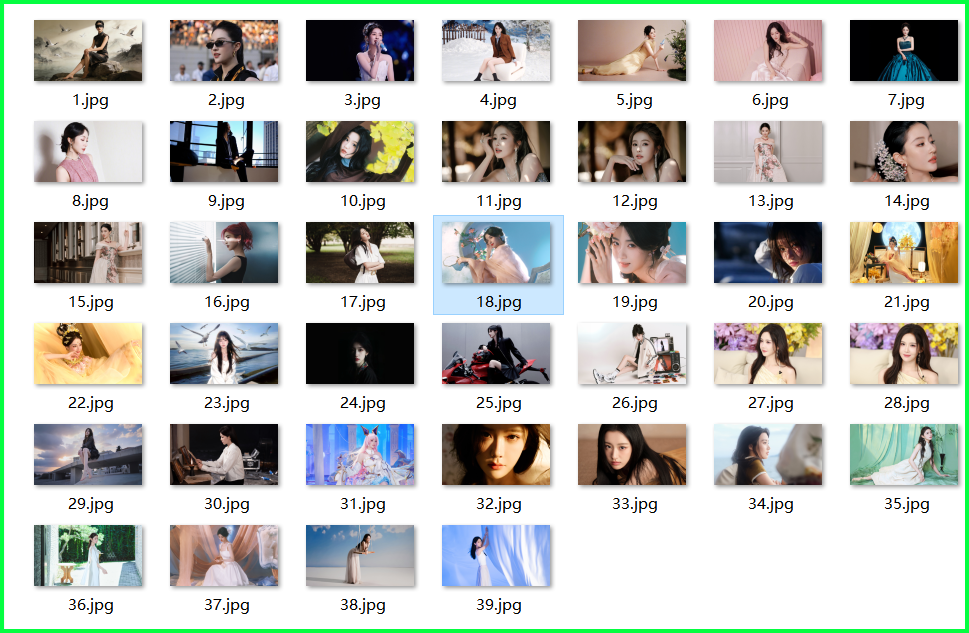
通过这个脚本,我们成功实现了对彼岸桌面美女壁纸的批量抓取。相比于之前的代码,这个版本更加健壮,能够自动处理多页、自动创建目录,并加入了必要的反爬措施。
⚠️ 友情提示:
- 爬虫仅供学习交流,请勿用于商业用途。
- 请合理控制爬取频率,做一个文明的爬虫工程师。
快运行代码试试吧!你的 images_netbian 文件夹很快就会被填满!