

专栏导读
🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手
🏳️🌈 个人博客主页:请点击——> 个人的博客主页 求收藏
🏳️🌈 Github主页:请点击——> Github主页 求Star⭐
🏳️🌈 知乎主页:请点击——> 知乎主页 求关注
🏳️🌈 CSDN博客主页:请点击——> CSDN的博客主页 求关注
👍 该系列文章专栏:请点击——>Python办公自动化专栏 求订阅
🕷 此外还有爬虫专栏:请点击——>Python爬虫基础专栏 求订阅
📕 此外还有python基础专栏:请点击——>Python基础学习专栏 求订阅
文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
❤️ 欢迎各位佬关注! ❤️
前言
在日常工作中,我们经常需要从 PDF 文档中提取数据或素材。手动复制粘贴不仅效率低下,而且容易出错。今天,我们将使用 Python 和 Streamlit 快速搭建一个可视化的 PDF 处理工具,实现自动提取表格(并导出为 Excel)和图片的功能。
Github源码
Github源码
Github源码
为什么选择这个技术栈?
- Streamlit: 无需前端知识,用纯 Python 就能写出漂亮的 Web 界面,非常适合快速开发数据工具。
- pdfplumber: 目前 Python 生态中提取 PDF 表格效果最好的库之一,能精确识别表格边框。
- PyMuPDF (fitz): 处理 PDF 底层结构非常快,适合用来提取图片。
- Pandas: 数据处理的神器,配合 OpenPyXL 可以轻松生成 Excel 文件。
核心功能实现
1. 环境搭建
首先,我们需要安装必要的库。创建一个 requirements.txt 文件:
streamlit
pdfplumber
pandas
openpyxl
pymupdf
然后执行 pip install -r requirements.txt。
2. 构建 Streamlit 界面
我们只需要几行代码就能搭建出文件上传和选项卡的界面:
import streamlit as st
st.set_page_config(page_title="PDF工具箱", layout="wide")
st.title("📄 PDF 表格与图片提取工具")
uploaded_file = st.file_uploader("请上传 PDF 文件", type=["pdf"])
if uploaded_file:
tab1, tab2 = st.tabs(["📊 表格提取", "🖼️ 图片提取"])
# 后续逻辑写在这里
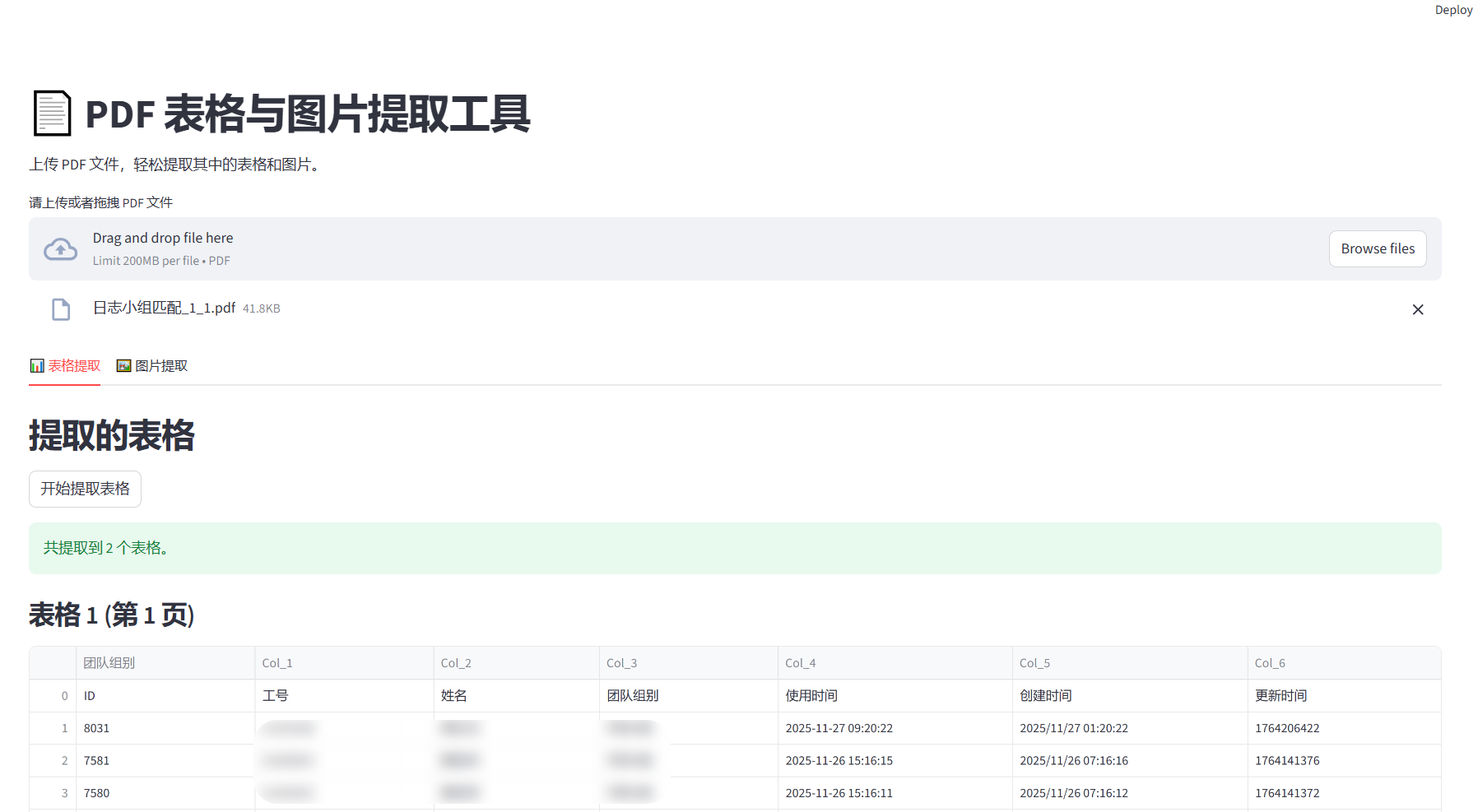
3. 提取表格并导出 Excel
使用 pdfplumber 打开 PDF,遍历每一页查找表格。为了方便用户下载,我们使用 pandas 将表格数据写入 Excel 的不同 Sheet 中。
关键代码片段:
import pdfplumber
import pandas as pd
import io
# ... 在 tab1 中 ...
if st.button("开始提取表格"):
with pdfplumber.open(uploaded_file) as pdf:
# 创建一个 BytesIO 对象用于在内存中保存 Excel 文件
output = io.BytesIO()
with pd.ExcelWriter(output, engine='openpyxl') as writer:
for i, page in enumerate(pdf.pages):
tables = page.extract_tables()
for j, table in enumerate(tables):
df = pd.DataFrame(table[1:], columns=table[0])
# 写入 Excel
sheet_name = f"Page_{i+1}_Table_{j+1}"
df.to_excel(writer, sheet_name=sheet_name[:31], index=False)
output.seek(0)
st.download_button("下载 Excel", output, "tables.xlsx")
4. 提取图片
对于图片提取,PyMuPDF (fitz) 更加高效。我们需要遍历 PDF 的对象列表(XREF),找到图片对象并提取其二进制数据。
关键代码片段:
import fitz
from PIL import Image
# ... 在 tab2 中 ...
if st.button("开始提取图片"):
# 注意:Streamlit 的 uploaded_file 需要读取为 bytes 给 fitz 使用
doc = fitz.open(stream=uploaded_file.read(), filetype="pdf")
for page in doc:
image_list = page.get_images(full=True)
for img in image_list:
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# 展示图片
st.image(image_bytes)
# 提供下载按钮
st.download_button("下载图片", image_bytes, file_name="image.png")
5. 遇到的坑与解决方案
- 文件指针问题:
uploaded_file是一个流对象。如果先被pdfplumber读取了,指针会跑到文件末尾。再传给fitz时就会报错。解决方案是在每次读取前调用.seek(0),或者一次性读取为bytes并在内存中复用。 - Excel Sheet 名称限制: Excel 的 Sheet 名称不能超过 31 个字符,且不能包含特殊字符。在写入时需要做截断处理。
- 扫描版 PDF: 对于全是图片的扫描版 PDF,上述方法无法提取表格文字。这种情况需要引入 OCR(如 PaddleOCR),但这会显著增加复杂度和运行时间。
总结
通过不到 100 行代码,我们就构建了一个实用的办公自动化工具。Streamlit 让我们可以专注于核心逻辑,而无需纠结于 HTML/CSS 的细节。这个工具可以轻松扩展,比如增加 PDF 合并、拆分、转 Word 等功能。
希望这篇教程对你有帮助!完整代码请参考项目仓库。
结尾 -
希望对初学者有帮助;致力于办公自动化的小小程序员一枚 -
希望能得到大家的【❤️一个免费关注❤️】感谢! -
求个 🤞 关注 🤞 +❤️ 喜欢 ❤️ +👍 收藏 👍 -
此外还有办公自动化专栏,欢迎大家订阅:Python办公自动化专栏 -
此外还有爬虫专栏,欢迎大家订阅:Python爬虫基础专栏 -
此外还有Python基础专栏,欢迎大家订阅:Python基础学习专栏