

🚀 纯前端实现!打造一个安全高效的 PDF 提取工具箱
在日常工作中,我们经常遇到需要从 PDF 中提取数据的情况:
- “老板发来一个 PDF 里的财务报表,让我转成 Excel。”
- “设计师给了 PDF 格式的作品集,我想把里面的高清原图提取出来。”
市面上的在线工具往往需要上传文件,对于敏感数据(如合同、财报)来说存在安全隐患;而桌面软件安装又太繁琐。
今天,我为大家带来一个纯前端、零后端、完全本地化运行的 PDF 提取工具箱。
在线使用请点击我跳转
在线使用请点击我跳转
在线使用请点击我跳转
✨ 核心功能
这个工具主要解决了两个痛点:表格提取 和 图片提取。
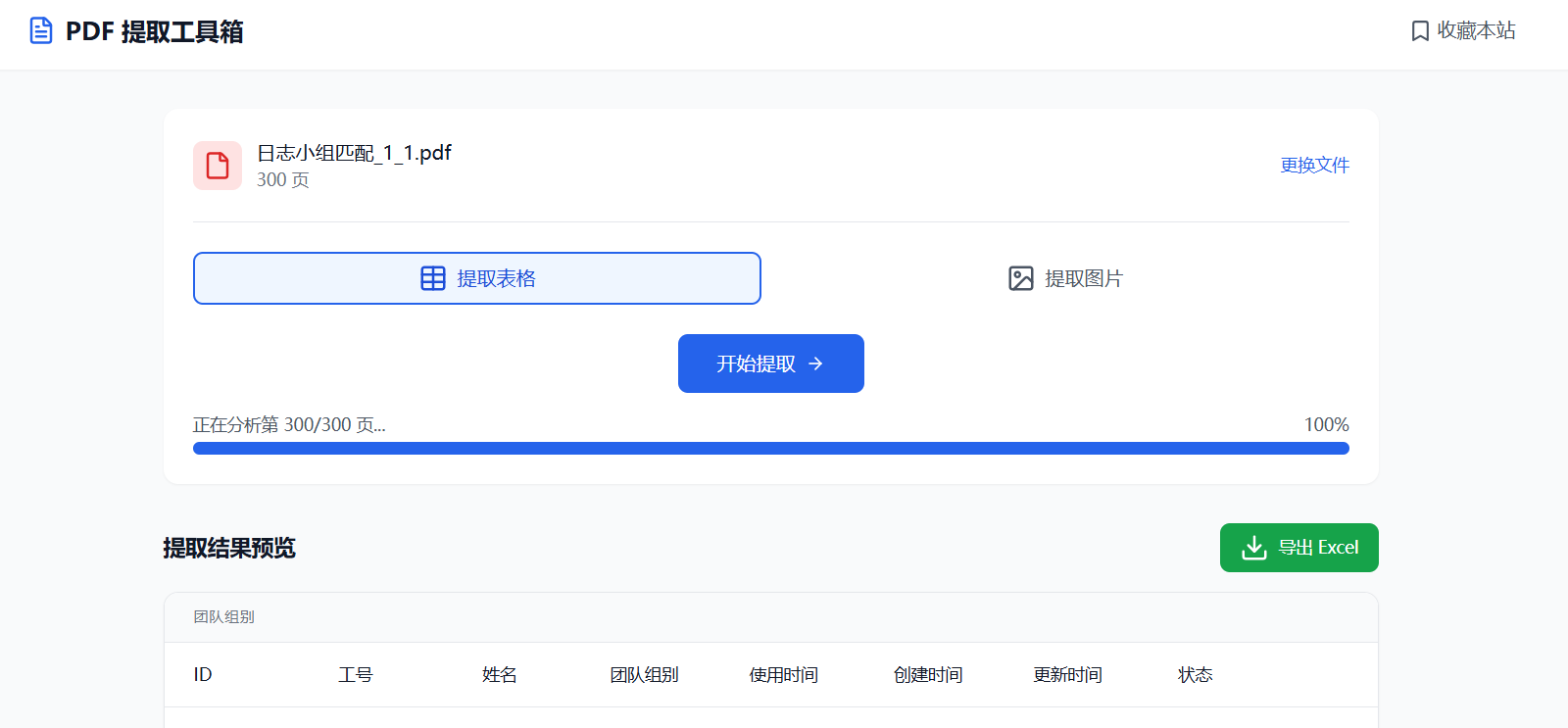
1. PDF 转 Excel (表格提取)
PDF 本质上是一种排版格式,并没有“表格”的语义结构。很多工具只是简单地把文字复制出来。
本工具通过分析文本在页面上的 X/Y 坐标,利用启发式算法智能重组行和列,尽可能还原表格结构,并支持一键导出为 .xlsx 文件。
2. PDF 图片无损提取
不是截图,而是提取原图。
工具直接深入 PDF 文件流,解析底层的 XObject 对象,将内嵌的图片资源完整提取出来。无论是 JPEG 还是 PNG,都能原样保存,并支持打包为 ZIP 下载。
3. 🔒 100% 隐私安全
这是本工具最大的亮点。
- 无后端:所有代码都运行在你的浏览器里(Chrome/Edge/Safari 等)。
- 无上传:你的文件从未离开过你的电脑,不用担心敏感数据泄露。
- 离线可用:页面加载完后,断网也能照常工作。
🛠️ 技术揭秘
这个项目是基于现代 Web 技术构建的,主要用到了以下开源库:
- PDF.js (Mozilla): 这是一个极其强大的库,用于在浏览器中解析和渲染 PDF。我们用它来获取 PDF 的文本内容(
getTextContent)和操作列表(getOperatorList)。 - SheetJS (xlsx): 前端最流行的电子表格处理库,用于将我们重组好的数据生成 Excel 文件。
- JSZip: 用于在浏览器端生成 ZIP 压缩包,方便批量下载图片。
- Tailwind CSS: 用于快速构建现代化的、响应式的用户界面。
核心代码逻辑浅析
表格提取算法:
// 简化的逻辑伪代码
items.forEach(item => {
const y = item.transform[5]; // 获取 Y 坐标
// 容差匹配:如果 Y 坐标相差在 5px 以内,视为同一行
let row = findRow(y);
if (!row) row = createNewRow(y);
row.push({ text: item.str, x: item.transform[4] });
});
// 最后按 X 坐标对行内元素排序,即可还原表格
图片提取逻辑:
PDF 中的图片通常是通过 paintImageXObject 操作符绘制的。我们可以遍历每一页的操作列表,拦截这个指令,从而获取图片对象引用,再通过 Canvas 将其转换为图片文件。
📖 如何使用
- 打开网站:直接在浏览器打开
index.html(或部署后的地址)。 - 拖拽文件:将你的 PDF 文件拖入上传区域。
- 选择功能:
- 点击 “提取表格” -> 预览数据 -> 点击 “导出 Excel”。
- 点击 “提取图片” -> 预览所有图片 -> 点击 “下载全部 (ZIP)”。
- 收藏本站:建议按
Ctrl+D收藏,以备不时之需。
🔮 未来计划
虽然目前版本已经能满足基础需求,但还有优化空间:
- 支持 OCR 文字识别(针对扫描版 PDF)。
- 更复杂的表格结构识别(如合并单元格处理)。
- 支持多文件批量处理。
如果你觉得这个工具好用,欢迎分享给身边的朋友!让我们一起用技术提高工作效率。💪
