

🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双
💻 个人主页——>个人主页欢迎访问
😸 Github主页——>Github主页欢迎访问
❓ 知乎主页——>知乎主页欢迎访问
🏳️🌈 CSDN博客主页:请点击——> 一晌小贪欢的博客主页求关注
👍 该系列文章专栏:请点击——>Python办公自动化专栏求订阅
🕷 此外还有爬虫专栏:请点击——>Python爬虫基础专栏求订阅
📕 此外还有python基础专栏:请点击——>Python基础学习专栏求订阅
文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
❤️ 欢迎各位佬关注! ❤️
前言
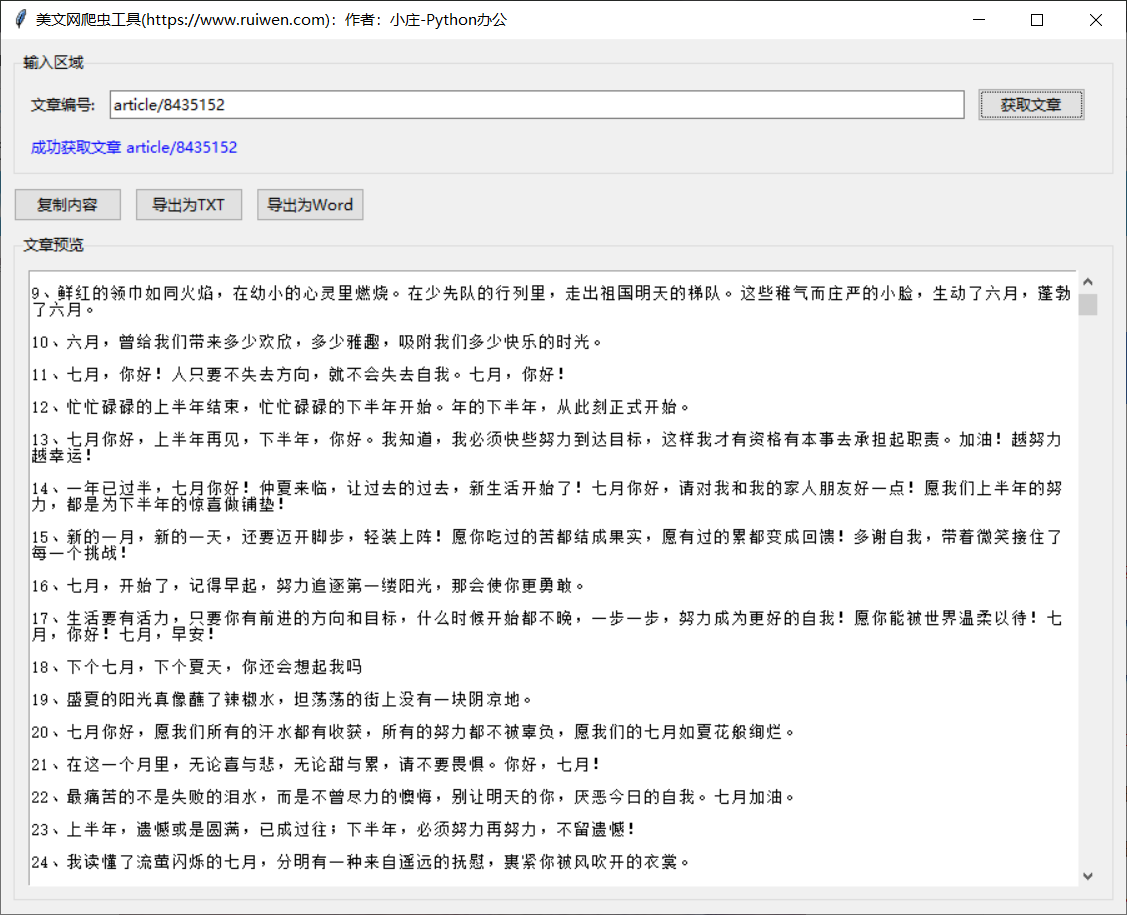
在日常的数据采集工作中,我们经常需要从各种网站获取内容。虽然命令行工具功能强大,但对于非技术用户来说,图形界面更加友好和直观。本文将详细介绍如何使用Python的tkinter库开发一个美文网爬虫GUI工具,实现文章内容的获取、预览、复制和导出功能。
Github
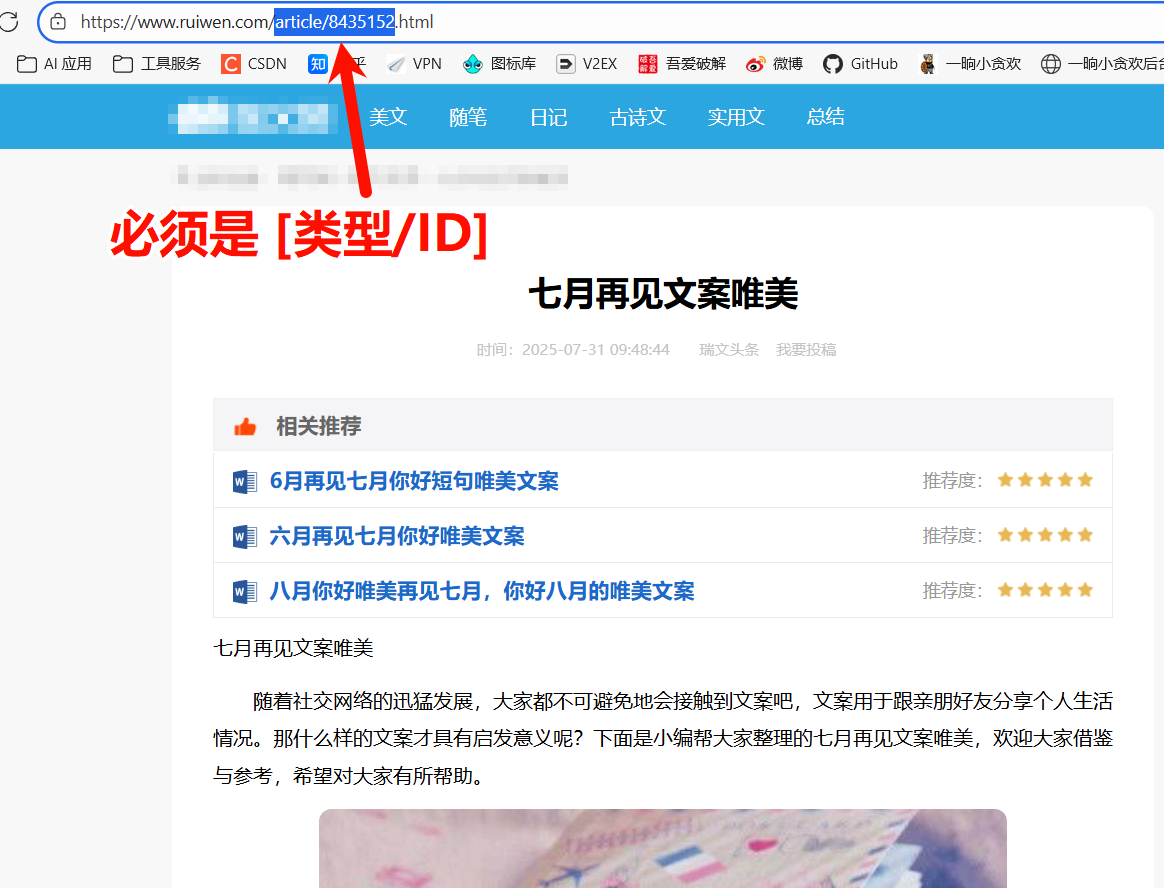
源码下载:瑞文网文章爬虫(https://www.ruiwen.com/)
打包下载:美文网文章获取器资源
项目概述
功能特点
- 🖥️ 友好的图形用户界面
- 📝 支持输入文章编号获取内容
- 👀 实时预览文章内容
- 📋 一键复制到剪贴板
- 📄 导出为TXT格式
- 📖 导出为Word文档格式
- ⚡ 多线程处理,避免界面卡顿
- 🛡️ 完善的错误处理机制
技术栈
- GUI框架: tkinter (Python内置)
- HTTP请求: requests
- 正则表达式: re
- Word文档处理: python-docx
- 多线程: threading
核心代码解析
1. 项目结构设计
class MeiwenCrawlerGUI:
def __init__(self, root):
self.root = root
self.root.title("美文网爬虫工具(https://www.ruiwen.com):作者:小庄-Python办公")
self.root.geometry("900x700")
# 请求头和cookies配置
self.headers = {...}
self.cookies = {...}
self.organized_content = {}
self.setup_ui()
这里采用了面向对象的设计模式,将整个GUI应用封装在一个类中。在初始化方法中,我们设置了窗口标题、大小,并配置了HTTP请求所需的headers和cookies。
2. 界面布局设计
主框架结构
def setup_ui(self):
# 主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 配置网格权重
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1)
main_frame.columnconfigure(1, weight=1)
main_frame.rowconfigure(2, weight=1)
使用 ttk.Frame作为主容器,通过 grid布局管理器实现响应式设计。设置权重确保界面能够自适应窗口大小变化。
输入区域设计
# 输入区域
input_frame = ttk.LabelFrame(main_frame, text="输入区域", padding="10")
input_frame.grid(row=0, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=(0, 10))
ttk.Label(input_frame, text="文章编号:").grid(row=0, column=0, sticky=tk.W, padx=(0, 10))
self.article_id_var = tk.StringVar()
self.article_entry = ttk.Entry(input_frame, textvariable=self.article_id_var, width=30)
self.article_entry.grid(row=0, column=1, sticky=(tk.W, tk.E), padx=(0, 10))
self.fetch_btn = ttk.Button(input_frame, text="获取文章", command=self.fetch_article_threaded)
self.fetch_btn.grid(row=0, column=2, padx=(0, 10))
输入区域包含标签、输入框和按钮,使用 StringVar绑定输入框的值,便于后续获取用户输入。
预览区域设计
# 预览区域
preview_frame = ttk.LabelFrame(main_frame, text="文章预览", padding="10")
preview_frame.grid(row=2, column=0, columnspan=2, sticky=(tk.W, tk.E, tk.N, tk.S))
self.preview_text = scrolledtext.ScrolledText(preview_frame, wrap=tk.WORD, state="disabled")
self.preview_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
使用 ScrolledText组件创建可滚动的文本预览区域,设置为只读状态,防止用户误操作。
3. 网络请求与数据处理
多线程请求处理
def fetch_article_threaded(self):
"""在新线程中获取文章,避免界面卡顿"""
thread = threading.Thread(target=self.fetch_article)
thread.daemon = True
thread.start()
为了避免网络请求阻塞GUI主线程,使用 threading模块在后台线程中执行请求操作。设置 daemon=True确保主程序退出时子线程也会结束。
网络请求实现
def fetch_article(self):
"""获取文章内容"""
article_id = self.article_id_var.get().strip()
if not article_id:
messagebox.showwarning("警告", "请输入文章编号")
return
self.status_var.set("正在获取文章...")
self.fetch_btn.config(state="disabled")
try:
url = f"https://www.ruiwen.com/pic/dldoc/page1/{article_id}.html.txt"
response = requests.get(url, headers=self.headers, cookies=self.cookies, timeout=10)
if response.status_code != 200:
raise Exception(f"HTTP错误: {response.status_code}")
data = response.json()
if 'body' not in data:
raise Exception("响应数据格式错误")
text = data['body']
self.organized_content = self.parse_content(text)
if not self.organized_content:
raise Exception("未找到有效内容")
self.display_content()
self.enable_buttons()
self.status_var.set(f"成功获取文章 {article_id}")
except requests.exceptions.Timeout:
self.status_var.set("请求超时,请重试")
messagebox.showerror("错误", "请求超时,请检查网络连接")
except requests.exceptions.RequestException as e:
self.status_var.set("网络请求失败")
messagebox.showerror("错误", f"网络请求失败: {str(e)}")
except Exception as e:
self.status_var.set("获取文章失败")
messagebox.showerror("错误", f"获取文章失败: {str(e)}")
finally:
self.fetch_btn.config(state="normal")
这个方法实现了完整的错误处理机制:
- 输入验证
- 网络超时处理
- HTTP状态码检查
- JSON数据格式验证
- 用户友好的错误提示
4. 内容解析与处理
HTML内容解析
def parse_content(self, text):
"""解析文章内容"""
# 使用正则表达式分割文本,同时保留标签信息
pattern = r'(<h2>.*?</h2>|<p>.*?</p>)'
elements = re.findall(pattern, text, re.DOTALL)
# 组织内容:按h2标题分组p标签内容
organized_content = {}
current_title = "前言" # 第一个h2标签之前的内容
for element in elements:
if element.startswith('<h2>'):
# 提取h2标题文本
title_match = re.search(r'<h2>(.*?)</h2>', element, re.DOTALL)
if title_match:
current_title = re.sub(r'\s+', ' ', title_match.group(1).strip())
organized_content[current_title] = []
elif element.startswith('<p>'):
# 提取p标签文本
p_match = re.search(r'<p>(.*?)</p>', element, re.DOTALL)
if p_match:
p_text = re.sub(r'\s+', ' ', p_match.group(1).strip())
# 清理HTML标签
p_text = re.sub(r'<[^>]+>', '', p_text)
if current_title not in organized_content:
organized_content[current_title] = []
organized_content[current_title].append(p_text)
return organized_content
使用正则表达式解析HTML内容:
- 提取所有
<h2>和<p>标签 - 按标题对段落进行分组
- 清理HTML标签,获取纯文本内容
- 规范化空白字符
内容显示与样式设置
def display_content(self):
"""在预览区域显示内容"""
self.preview_text.config(state="normal")
self.preview_text.delete(1.0, tk.END)
for title, paragraphs in self.organized_content.items():
self.preview_text.insert(tk.END, f"【{title}】\n", "title")
for i, para in enumerate(paragraphs, 1):
self.preview_text.insert(tk.END, f"\n{para}\n")
self.preview_text.insert(tk.END, "\n" + "="*50 + "\n\n")
# 配置标题样式
self.preview_text.tag_config("title", font=("微软雅黑", 12, "bold"), foreground="#2E86AB")
self.preview_text.config(state="disabled")
通过 tag_config方法为标题设置特殊样式,使用不同的字体、大小和颜色来区分标题和正文。
5. 导出功能实现
复制到剪贴板
def copy_content(self):
"""复制内容到剪贴板"""
if not self.organized_content:
messagebox.showwarning("警告", "没有可复制的内容")
return
content = self.format_content_for_text()
self.root.clipboard_clear()
self.root.clipboard_append(content)
messagebox.showinfo("成功", "内容已复制到剪贴板")
使用tkinter内置的剪贴板操作方法,实现一键复制功能。
TXT文件导出
def export_txt(self):
"""导出为TXT文件"""
if not self.organized_content:
messagebox.showwarning("警告", "没有可导出的内容")
return
filename = filedialog.asksaveasfilename(
defaultextension=".txt",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")],
title="保存TXT文件"
)
if filename:
try:
content = self.format_content_for_text()
with open(filename, 'w', encoding='utf-8') as f:
f.write(content)
messagebox.showinfo("成功", f"文件已保存到: {filename}")
except Exception as e:
messagebox.showerror("错误", f"保存文件失败: {str(e)}")
使用 filedialog.asksaveasfilename提供文件保存对话框,支持用户自定义保存位置和文件名。
Word文档导出
def export_word(self):
"""导出为Word文件"""
if not self.organized_content:
messagebox.showwarning("警告", "没有可导出的内容")
return
filename = filedialog.asksaveasfilename(
defaultextension=".docx",
filetypes=[("Word文档", "*.docx"), ("所有文件", "*.*")],
title="保存Word文件"
)
if filename:
try:
doc = Document()
for title, paragraphs in self.organized_content.items():
# 添加标题
heading = doc.add_heading(title, level=1)
heading.alignment = 1 # 居中对齐
# 添加段落
for para in paragraphs:
p = doc.add_paragraph(para)
p.alignment = 0 # 左对齐
# 添加分隔线
doc.add_paragraph("="*50)
doc.save(filename)
messagebox.showinfo("成功", f"Word文档已保存到: {filename}")
except Exception as e:
messagebox.showerror("错误", f"保存Word文档失败: {str(e)}")
使用 python-docx库创建格式化的Word文档,包括标题样式、段落对齐等。
用户体验优化
1. 界面交互优化
- 回车键绑定: 在输入框中按回车键即可触发获取文章操作
- 按钮状态管理: 在没有内容时禁用导出和复制按钮
- 状态提示: 实时显示操作状态和结果
2. 错误处理机制
- 网络异常: 超时、连接失败等网络问题的处理
- 数据异常: 响应格式错误、内容为空等数据问题的处理
- 文件操作异常: 文件保存失败等IO问题的处理
3. 性能优化
- 多线程处理: 避免网络请求阻塞GUI主线程
- 内存管理: 及时清理不需要的数据
- 响应式设计: 界面能够适应不同窗口大小
部署与使用
依赖安装
pip install requests python-docx
运行程序
def main():
root = tk.Tk()
app = MeiwenCrawlerGUI(root)
root.mainloop()
if __name__ == "__main__":
main()
使用步骤
- 运行程序启动GUI界面
- 在"文章编号"输入框中输入目标文章的编号
- 点击"获取文章"按钮或按回车键
- 等待文章加载完成,在预览区域查看内容
- 根据需要选择复制、导出TXT或导出Word功能
扩展功能建议
1. 批量处理
可以扩展支持批量获取多篇文章,添加文章列表管理功能。
2. 搜索功能
在预览区域添加搜索功能,支持关键词高亮显示。
3. 主题切换
支持明暗主题切换,提供更好的视觉体验。
4. 配置管理
添加配置文件支持,允许用户自定义请求头、超时时间等参数。
5. 历史记录
保存获取过的文章历史记录,支持快速重新访问。
总结
本文详细介绍了如何使用Python tkinter开发一个功能完整的美文网爬虫GUI工具。通过面向对象的设计模式、多线程处理、完善的错误处理机制和用户友好的界面设计,我们创建了一个既实用又易用的桌面应用程序。
这个项目展示了以下几个重要的开发技巧:
- GUI设计: 使用tkinter创建响应式界面布局
- 网络编程: 处理HTTP请求和响应
- 数据处理: 使用正则表达式解析HTML内容
- 文件操作: 支持多种格式的文件导出
- 多线程编程: 避免界面卡顿的异步处理
- 错误处理: 完善的异常处理和用户提示
通过这个项目,我们不仅学会了如何开发GUI应用程序,还掌握了网络爬虫、数据处理和文档生成等多个技术领域的知识。这些技能可以应用到更多的实际项目中,为日常工作提供便利的自动化工具。
希望这篇文章能够帮助你理解GUI应用程序的开发流程,并激发你创建更多有用工具的灵感!
希望对初学者有帮助;致力于办公自动化的小小程序员一枚
希望能得到大家的【❤️一个免费关注❤️】感谢!
求个 🤞 关注 🤞 +❤️ 喜欢 ❤️ +👍 收藏 👍
此外还有办公自动化专栏,欢迎大家订阅:Python办公自动化专栏
此外还有爬虫专栏,欢迎大家订阅:Python爬虫基础专栏
此外还有Python基础专栏,欢迎大家订阅:Python基础学习专栏
