

🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手
🏳️🌈 个人博客主页:请点击——> 个人的博客主页 求收藏
🏳️🌈 Github主页:请点击——> Github主页 求Star⭐
🏳️🌈 知乎主页:请点击——> 知乎主页 求关注
🏳️🌈 CSDN博客主页:请点击——> CSDN的博客主页 求关注
👍 该系列文章专栏:请点击——>Python办公自动化专栏 求订阅
🕷 此外还有爬虫专栏:请点击——>Python爬虫基础专栏 求订阅
📕 此外还有python基础专栏:请点击——>Python基础学习专栏 求订阅
文章作者技术和水平有限,如果文中出现错误,希望大家能指正🙏
❤️ 欢迎各位佬关注! ❤️
Python实战:打造高效Excel数据合并工具 (PyQt5 + Pandas)
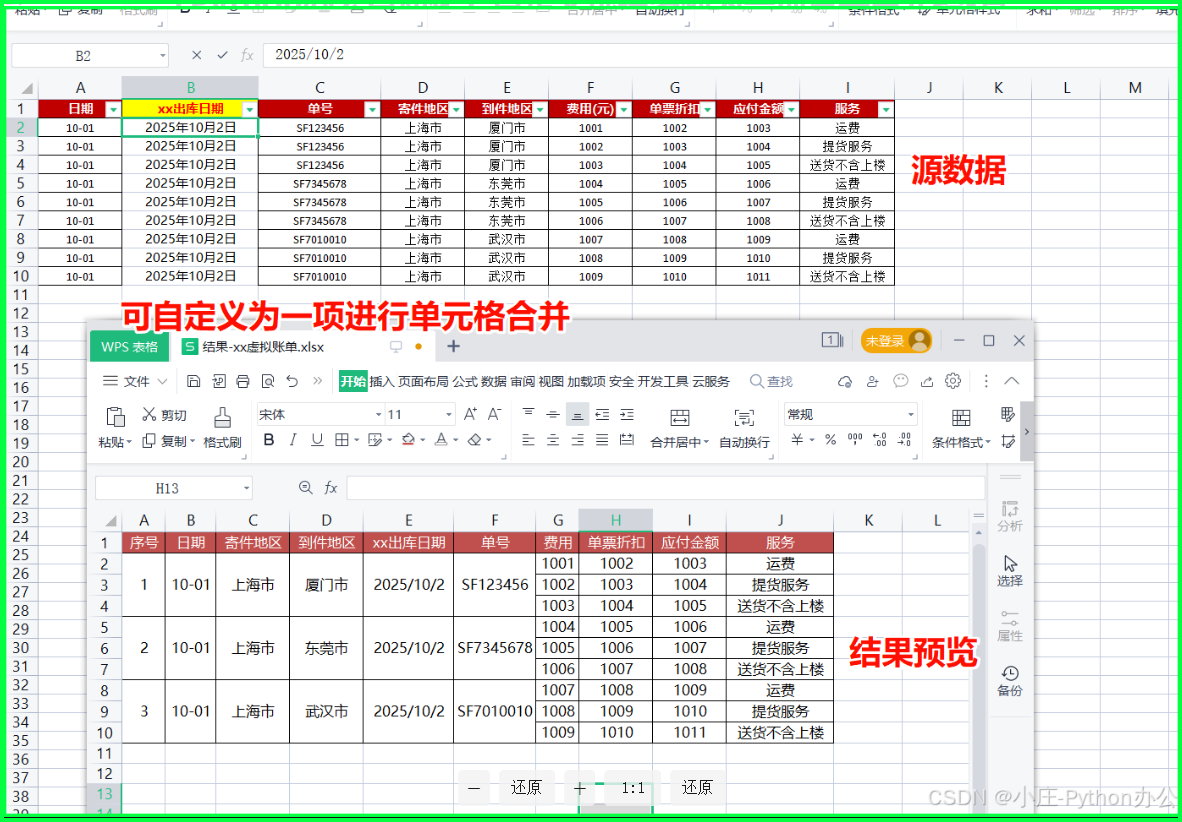
在日常的数据处理工作中,我们经常遇到需要对Excel表格进行“合并单元格”操作的场景。例如,物流对账单、订单列表等,往往有多行数据属于同一个订单(如运单号相同),但具体的费用项(运费、提货费等)是分开列出的。为了生成清晰的对账单,我们需要将相同订单的信息合并显示,而保留明细行。
手动操作不仅费时费力,还容易出错。本文将介绍如何使用 Python (Pandas, Openpyxl) 和 PyQt5 开发一个带有图形界面的 Excel 合并工具,实现自动化处理。
Github链接: Excel唯一项合并单元格-其余不合并
1. 项目背景与需求
痛点:
- 原始数据通常是“一维”的清单,重复信息(如订单号、日期)在每一行都显示。
- 财务或业务部门需要查看“合并版”报表,即相同的订单信息合并单元格,右侧展示明细。
- 需要同时生成 JSON 数据供其他系统使用。
解决方案:
开发一个桌面小工具,用户只需选择 Excel 文件,勾选作为“合并依据”的列(Key),程序自动完成分组、合并和导出。
2. 核心功能
- 图形化界面 (GUI):基于 PyQt5,操作简单直观。
- 灵活的列选择:自动读取 Excel 表头,用户可勾选哪些列作为 Key(合并依据),未勾选的列作为 Detail(明细)。
- 智能日期处理:自动识别包含“日期”、“时间”、“Date”、“Time”的列,并统一格式化为
YYYY-MM-DD,解决 Excel 数字序列号(如 45932)的问题。 - 数据清洗:自动处理科学计数法(如
1.23E+11),去除无效的空行。 - 双重输出:
- Excel:生成的表格中,Key 列自动合并单元格,且居中显示。
- JSON:生成结构化的 JSON 数据,方便后续 API 调用或存档。
3. 技术栈
- Python 3.x
- Pandas: 强大的数据处理库,用于读取和分组数据。
- Openpyxl: 用于操作 Excel 文件,核心的
merge_cells功能依赖它。 - PyQt5: 构建桌面应用程序界面。
- Calamine: (可选) 配合 Pandas 使用的高性能 Excel 读取引擎。
4. 实现细节
4.1 数据读取与预处理
使用 pandas 读取 Excel,为了防止精度丢失(如长数字变成科学计数法),我们统一读取为字符串格式,后续再按需转换。
# 核心代码片段
self.df = pd.read_excel(
self.file_path,
sheet_name=sheet_name,
header=header_row,
engine='calamine', # 加速读取
dtype=str # 强制字符串,避免精度丢失
)
4.2 智能日期格式化
Excel 中的日期有时会存储为浮点数(序列号),有时是字符串。我们需要一个健壮的函数来统一它们。
def format_excel_date(value: Any) -> str:
"""
处理Excel日期格式,支持:
1. 字符串 '2023-01-01'
2. datetime 对象
3. Excel序列号 (float/int) e.g. 45932.0
"""
# ... 省略部分判断代码 ...
# 针对 Excel 序列号的处理
if isinstance(value, (int, float)):
try:
dt = datetime(1899, 12, 30) + timedelta(days=float(value))
return dt.strftime('%Y-%m-%d')
except Exception:
return str(value)
# ... 其他解析逻辑 ...
在最新的更新中,我们还加入了自动关键词检测:
# 自动识别日期列
date_keywords = ['日期', '时间', 'Date', 'Time']
for col in processed_df.columns:
if any(keyword in str(col) for keyword in date_keywords):
processed_df[col] = processed_df[col].apply(format_excel_date)
4.3 分组与合并逻辑
这是工具的核心。我们需要根据用户选定的 Key 列,将数据分组。
- 构建 Key:将每一行选中的 Key 列组合成一个 tuple。
- 分组:遍历数据,将相同 Key 的行归类到同一个列表。
- 写入与合并:使用
openpyxl写入数据,并根据每组的起始行和结束行调用ws.merge_cells。
# 写入逻辑示意
for key_tuple, items in groups.items():
start_row = row_num
# 写入多行明细
for item in items:
# ... 写入 Detail 列 ...
row_num += 1
end_row = row_num - 1
# 合并 Key 列
if end_row > start_row:
for i in range(len(key_columns)):
ws.merge_cells(start_row=start_row, start_column=i+2, end_row=end_row, end_column=i+2)
4.4 JSON 输出
除了 Excel,工具还会生成如下结构的 JSON,Key 是合并列的组合字符串,Value 是明细列表:
{
"2023-10-21_SF123456_上海_北京": [
{
"序号": 1,
"费用": 100.0,
"服务": "运费"
},
{
"序号": 2,
"费用": 20.0,
"服务": "包装费"
}
]
}
完整代码
import sys
import json
import os
import pandas as pd
import openpyxl
from openpyxl.styles import Alignment
from datetime import datetime, timedelta
from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout,
QHBoxLayout, QPushButton, QLabel, QFileDialog,
QComboBox, QSpinBox, QTableWidget, QTableWidgetItem,
QCheckBox, QScrollArea, QMessageBox, QGroupBox, QSplitter)
from PyQt5.QtCore import Qt
from typing import Any, List, Dict
# 标准列定义 (参考 main.py)
STANDARD_KEY_COLUMNS = [
"日期", "清美出库日期", "运单号码", "清美系统订单号",
"寄件地区", "到件地区", "对方公司名称", "箱数", "计费重量", "产品类型"
]
# 需要重命名的列 (原名 -> 新名)
COLUMN_MAPPING = {
"费用(元)": "费用"
}
# 复用 main.py 中的日期格式化函数
def format_excel_date(value: Any) -> str:
"""
处理Excel日期格式,支持:
1. 字符串 '2023-01-01'
2. datetime 对象
3. Excel序列号 (float/int) e.g. 45932.0
"""
if pd.isna(value) or value == '' or str(value).lower() == 'nan':
return ''
# 如果已经是datetime对象
if isinstance(value, datetime):
return value.strftime('%Y-%m-%d')
# 如果是数字(Excel序列号)
if isinstance(value, (int, float)):
try:
# Excel base date: 1899-12-30
dt = datetime(1899, 12, 30) + timedelta(days=float(value))
return dt.strftime('%Y-%m-%d')
except Exception:
return str(value)
# 如果是字符串,尝试解析
val_str = str(value).strip()
# 检查是否是数字字符串 '45932.0' 或 '45932'
try:
# 移除可能的小数点
if val_str.replace('.', '', 1).isdigit():
float_val = float(val_str)
if float_val > 10000: # 简单的阈值判断
dt = datetime(1899, 12, 30) + timedelta(days=float_val)
return dt.strftime('%Y-%m-%d')
except:
pass
# 尝试处理 timestamp
if hasattr(value, 'strftime'):
return value.strftime('%Y-%m-%d')
# 尝试使用 pd.to_datetime 解析常见日期字符串
try:
# 避免解析纯数字字符串(如果前面没捕获)
if not val_str.isdigit():
dt = pd.to_datetime(val_str, errors='coerce')
if not pd.isna(dt):
return dt.strftime('%Y-%m-%d')
except:
pass
return val_str
class ExcelMergerApp(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Excel合并工具 - 华东3组")
self.resize(1000, 800)
# 状态变量
self.file_path = ""
self.df = None
self.column_checkboxes = []
# 主布局
main_widget = QWidget()
self.setCentralWidget(main_widget)
layout = QVBoxLayout(main_widget)
layout.setContentsMargins(10, 10, 10, 10)
layout.setSpacing(10)
# 1. 顶部设置区域 (合并文件和读取设置,更加紧凑)
top_group = QGroupBox("设置")
top_layout = QVBoxLayout()
top_layout.setContentsMargins(5, 5, 5, 5)
top_layout.setSpacing(5)
# 第一行:文件选择
row1_layout = QHBoxLayout()
self.btn_select_file = QPushButton("选择Excel文件")
self.btn_select_file.clicked.connect(self.select_file)
self.lbl_file_path = QLabel("未选择文件")
self.lbl_file_path.setStyleSheet("color: gray; font-style: italic;")
row1_layout.addWidget(self.btn_select_file)
row1_layout.addWidget(self.lbl_file_path, 1) # Give label more stretch
top_layout.addLayout(row1_layout)
# 第二行:读取参数
row2_layout = QHBoxLayout()
row2_layout.addWidget(QLabel("Sheet名称:"))
self.combo_sheet = QComboBox()
self.combo_sheet.setMinimumWidth(150)
row2_layout.addWidget(self.combo_sheet)
row2_layout.addWidget(QLabel("表头行:"))
self.spin_header_row = QSpinBox()
self.spin_header_row.setRange(1, 100)
self.spin_header_row.setValue(2)
self.spin_header_row.setFixedWidth(60)
row2_layout.addWidget(self.spin_header_row)
self.btn_load_data = QPushButton("加载数据")
self.btn_load_data.clicked.connect(self.load_data)
row2_layout.addWidget(self.btn_load_data)
row2_layout.addStretch() # Push everything to the left
top_layout.addLayout(row2_layout)
top_group.setLayout(top_layout)
layout.addWidget(top_group)
# 2. 中间区域:列选择与预览 (使用Splitter)
splitter = QSplitter(Qt.Horizontal)
# 左侧:列选择
col_group = QGroupBox("合并列 (勾选为Key)")
col_layout = QVBoxLayout()
col_layout.setContentsMargins(5, 5, 5, 5)
# 全选/全不选
btn_layout = QHBoxLayout()
self.btn_check_all = QPushButton("全选")
self.btn_check_all.clicked.connect(lambda: self.toggle_all(True))
self.btn_uncheck_all = QPushButton("全不选")
self.btn_uncheck_all.clicked.connect(lambda: self.toggle_all(False))
btn_layout.addWidget(self.btn_check_all)
btn_layout.addWidget(self.btn_uncheck_all)
col_layout.addLayout(btn_layout)
# 滚动区域放复选框
scroll = QScrollArea()
scroll.setWidgetResizable(True)
self.scroll_content = QWidget()
self.scroll_layout = QVBoxLayout(self.scroll_content)
self.scroll_layout.setAlignment(Qt.AlignTop)
self.scroll_layout.setContentsMargins(2, 2, 2, 2)
self.scroll_layout.setSpacing(2)
scroll.setWidget(self.scroll_content)
col_layout.addWidget(scroll)
col_group.setLayout(col_layout)
splitter.addWidget(col_group)
# 右侧:数据预览
preview_group = QGroupBox("数据预览")
preview_layout = QVBoxLayout()
preview_layout.setContentsMargins(5, 5, 5, 5)
self.table_preview = QTableWidget()
preview_layout.addWidget(self.table_preview)
preview_group.setLayout(preview_layout)
splitter.addWidget(preview_group)
# 设置Splitter比例
splitter.setSizes([250, 750])
layout.addWidget(splitter, 1) # Stretch factor 1 makes it take available space
# 3. 底部执行区域
action_layout = QHBoxLayout()
self.btn_process = QPushButton("开始合并导出")
self.btn_process.setMinimumHeight(45)
self.btn_process.setStyleSheet("QPushButton { font-weight: bold; font-size: 16px; background-color: #4CAF50; color: white; border-radius: 5px; } QPushButton:disabled { background-color: #cccccc; } QPushButton:hover { background-color: #45a049; }")
self.btn_process.clicked.connect(self.process_data)
self.btn_process.setEnabled(False)
action_layout.addWidget(self.btn_process)
layout.addLayout(action_layout)
def select_file(self):
file_path, _ = QFileDialog.getOpenFileName(self, "选择Excel文件", "", "Excel Files (*.xlsx *.xls *.xlsm)")
if file_path:
self.file_path = file_path
self.lbl_file_path.setText(file_path)
self.load_sheets()
def load_sheets(self):
try:
# 只读取元数据,不读取内容,加快速度
xl = pd.ExcelFile(self.file_path, engine='calamine')
self.combo_sheet.clear()
self.combo_sheet.addItems(xl.sheet_names)
except Exception as e:
QMessageBox.critical(self, "错误", f"读取文件失败: {str(e)}")
def load_data(self):
if not self.file_path:
return
sheet_name = self.combo_sheet.currentText()
header_row = self.spin_header_row.value() - 1 # 转为0-based index
try:
# 读取数据
# 强制所有列为object/str,避免自动转换导致的精度丢失问题,后续手动处理
self.df = pd.read_excel(
self.file_path,
sheet_name=sheet_name,
header=header_row,
engine='calamine',
dtype=str
)
# 清理:移除全为空的行,但保留列(即使为空)以防表头丢失
self.df.dropna(how='all', axis=0, inplace=True)
# self.df.dropna(how='all', axis=1, inplace=True) # 不要移除空列,否则如果某列(如箱数)全为空,会被丢弃导致表头缺失
# 更新列选择器
self.update_column_selectors()
# 更新预览
self.update_preview()
self.btn_process.setEnabled(True)
QMessageBox.information(self, "成功", f"成功加载 {len(self.df)} 行数据")
except Exception as e:
QMessageBox.critical(self, "错误", f"加载数据失败: {str(e)}")
def update_column_selectors(self):
# 清除旧的复选框
for i in reversed(range(self.scroll_layout.count())):
self.scroll_layout.itemAt(i).widget().setParent(None)
self.column_checkboxes = []
if self.df is not None:
for col in self.df.columns:
cb = QCheckBox(str(col))
# 如果是标准Key列,默认选中
if str(col) in STANDARD_KEY_COLUMNS:
cb.setChecked(True)
else:
cb.setChecked(False)
self.scroll_layout.addWidget(cb)
self.column_checkboxes.append(cb)
def toggle_all(self, checked):
for cb in self.column_checkboxes:
cb.setChecked(checked)
def update_preview(self):
if self.df is None:
return
# 显示前50行
preview_df = self.df.head(50)
self.table_preview.setRowCount(len(preview_df))
self.table_preview.setColumnCount(len(preview_df.columns))
self.table_preview.setHorizontalHeaderLabels([str(c) for c in preview_df.columns])
for i in range(len(preview_df)):
for j in range(len(preview_df.columns)):
val = preview_df.iloc[i, j]
# 简单格式化显示
if pd.isna(val):
val = ""
self.table_preview.setItem(i, j, QTableWidgetItem(str(val)))
def process_data(self):
if self.df is None:
return
# 1. 获取选中的Key列
selected_columns = []
detail_columns = []
for i, cb in enumerate(self.column_checkboxes):
col_name = self.df.columns[i]
if cb.isChecked():
selected_columns.append(col_name)
else:
detail_columns.append(col_name)
# 强制按照 STANDARD_KEY_COLUMNS 的顺序排列 Key 列,以匹配 main.py 的输出格式
key_columns = []
# 先按标准顺序添加
for std_col in STANDARD_KEY_COLUMNS:
if std_col in selected_columns:
key_columns.append(std_col)
# 从选中列表中移除,避免重复(处理剩余列时)
# 注意:这里我们使用一个新的列表来存储剩余的,因为在迭代中修改列表是危险的
# 添加剩余的非标准Key列(如果有)
remaining_keys = [col for col in selected_columns if col not in key_columns]
key_columns.extend(remaining_keys)
if not key_columns:
QMessageBox.warning(self, "警告", "请至少选择一列作为合并依据(Key)")
return
try:
# 2. 选择保存路径
output_dir = os.path.dirname(self.file_path)
base_name = os.path.splitext(os.path.basename(self.file_path))[0]
default_save_path = os.path.join(output_dir, f"结果-{base_name}_gui.xlsx")
save_path, _ = QFileDialog.getSaveFileName(
self,
"保存导出文件",
default_save_path,
"Excel Files (*.xlsx)"
)
if not save_path:
return
# 3. 处理数据
# 预处理:格式化日期,处理科学计数法等
processed_df = self.df.copy()
# 定义日期列关键词
date_keywords = ['日期', '时间', 'Date', 'Time']
for col in processed_df.columns:
# 尝试识别日期列
if any(keyword in str(col) for keyword in date_keywords):
processed_df[col] = processed_df[col].apply(format_excel_date)
# 处理可能的数字字符串 .0 结尾
# 由于读取时用了 dtype=str,所有内容都是字符串
# 同时处理 'nan' 字符串,将其转换为空字符串
processed_df[col] = processed_df[col].astype(str).apply(
lambda x: "" if x == "nan" else (x[:-2] if x.endswith('.0') else x)
)
# 尝试修复科学计数法 (如果存在 'e+' 且看起来像数字)
# 这里简单处理,如果字符串包含e+且能转回数字,则尝试还原
def fix_sci(val):
if 'e+' in str(val).lower():
try:
return str(int(float(val)))
except:
return val
return val
processed_df[col] = processed_df[col].apply(fix_sci)
# 4. 分组逻辑 & 准备JSON数据
# 将Key列组合成一个元组作为字典的Key
groups = {}
json_data_dict = {}
for _, row in processed_df.iterrows():
# 构造Key tuple (用于Excel处理)
key_tuple = tuple(row[col] for col in key_columns)
# 构造Key string (用于JSON输出,参考 main.py 格式)
key_str = "_".join(str(row[col]) for col in key_columns)
if key_tuple not in groups:
groups[key_tuple] = []
if key_str not in json_data_dict:
json_data_dict[key_str] = []
# 构造Detail dict
detail_item = {}
for col in detail_columns:
# 获取列名,处理重命名
output_col_name = COLUMN_MAPPING.get(col, col)
val = row[col]
# 尝试转回数字以便计算或输出正确的JSON类型
final_val = val
try:
if isinstance(val, str) and val.replace('.','',1).isdigit():
if '.' in val:
final_val = float(val)
else:
final_val = int(val) # 如果是纯数字字符串
# 如果main.py要求是float,这里可能要注意。main.py对于 '费用' 等是 float()
# 为了保持一致,如果是特定列,强制 float
if output_col_name in ["费用", "单票折扣", "应付金额"]:
final_val = float(val)
# 如果已经是数字
elif isinstance(val, (int, float)):
if output_col_name in ["费用", "单票折扣", "应付金额"]:
final_val = float(val)
except:
pass
detail_item[output_col_name] = final_val
groups[key_tuple].append(detail_item)
json_data_dict[key_str].append(detail_item)
# 5. 写入Excel (Openpyxl)
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "处理结果"
# 写入表头
# Key列 + Detail列 (重命名后)
output_detail_headers = [COLUMN_MAPPING.get(col, col) for col in detail_columns]
headers = ["序号"] + key_columns + output_detail_headers
ws.append(headers)
row_num = 2
group_index = 1
for key_tuple, items in groups.items():
start_row = row_num
for item in items:
# 写入序号
ws.cell(row=row_num, column=1, value=group_index)
# 写入Key列
for i, val in enumerate(key_tuple):
ws.cell(row=row_num, column=i+2, value=val)
# 写入Detail列
for i, col_name in enumerate(output_detail_headers):
val = item.get(col_name, "")
ws.cell(row=row_num, column=len(key_columns)+i+2, value=val)
row_num += 1
end_row = row_num - 1
# 合并序号列
if end_row > start_row:
ws.merge_cells(start_row=start_row, start_column=1, end_row=end_row, end_column=1)
# 设置序号列居中
cell = ws.cell(row=start_row, column=1)
cell.alignment = Alignment(horizontal='center', vertical='center')
# 合并Key列
if end_row > start_row:
for i in range(len(key_columns)):
ws.merge_cells(start_row=start_row, start_column=i+2, end_row=end_row, end_column=i+2)
# 设置Key列居中
for i in range(len(key_columns)):
cell = ws.cell(row=start_row, column=i+2)
cell.alignment = Alignment(horizontal='center', vertical='center')
group_index += 1
wb.save(save_path)
# 6. 保存JSON (指定绝对目录)
json_output_dir = r'd:\I_LOVE_KUNKUN\12月\华东3组-董谷-清美-合单需求\json数据'
os.makedirs(json_output_dir, exist_ok=True)
base_filename = os.path.splitext(os.path.basename(save_path))[0]
# 移除 "结果-" 前缀如果存在,保持文件名整洁,或者直接用保存的文件名
json_filename = f"{base_filename}_data.json"
json_path = os.path.join(json_output_dir, json_filename)
with open(json_path, 'w', encoding='utf-8') as f:
json.dump(json_data_dict, f, ensure_ascii=False, indent=4)
QMessageBox.information(self, "完成", f"Excel文件已保存至:\n{save_path}\n\nJSON文件已保存至:\n{json_path}")
except Exception as e:
QMessageBox.critical(self, "错误", f"处理失败: {str(e)}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
app = QApplication(sys.argv)
window = ExcelMergerApp()
window.show()
sys.exit(app.exec_())
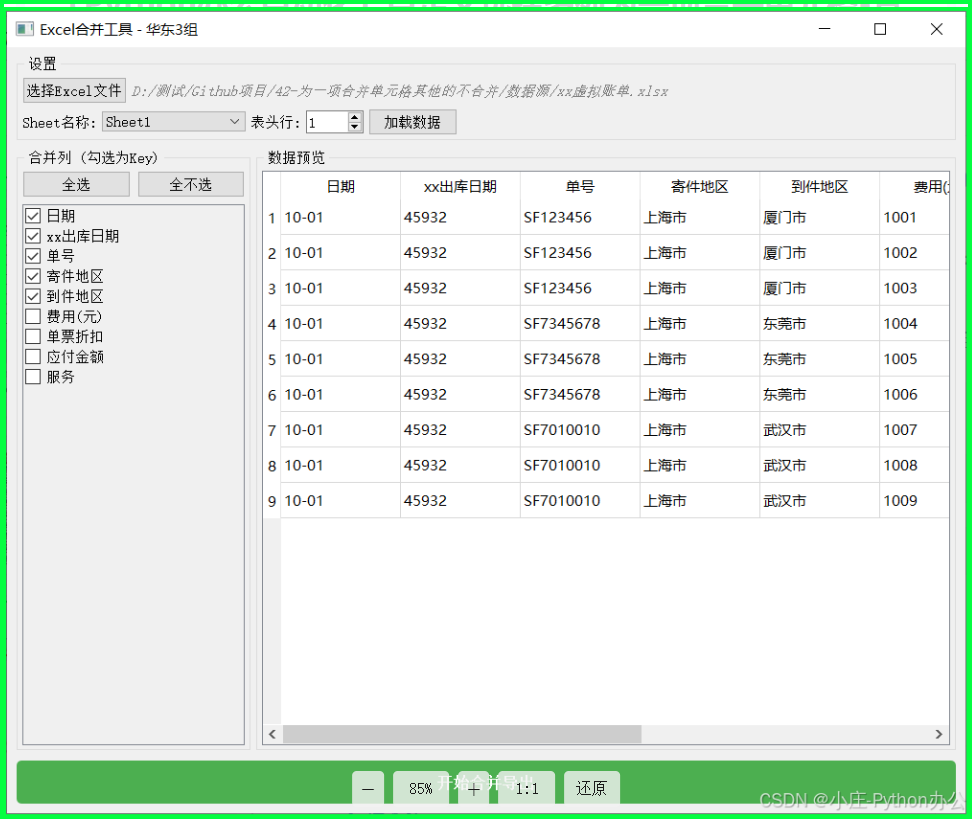
5. 界面预览
(此处可插入界面截图)
界面主要分为三部分:
- 顶部:选择文件、Sheet页及表头行数。
- 中部:左侧勾选需要合并的列(Key),右侧预览数据。
- 底部:一键生成结果。
6. 总结
通过 Python 编写这个小工具,我们极大地提高了对账单整理的效率。它展示了 Python 在办公自动化(RPA)领域的强大能力——不仅能处理数据,还能通过 GUI 方便非技术人员使用。
如果你也有类似的需求,不妨尝试自己动手实现一个!
希望对初学者有帮助;致力于办公自动化的小小程序员一枚
希望能得到大家的【❤️一个免费关注❤️】感谢!
求个 🤞 关注 🤞 +❤️ 喜欢 ❤️ +👍 收藏 👍
此外还有办公自动化专栏,欢迎大家订阅:Python办公自动化专栏
此外还有爬虫专栏,欢迎大家订阅:Python爬虫基础专栏
此外还有Python基础专栏,欢迎大家订阅:Python基础学习专栏