

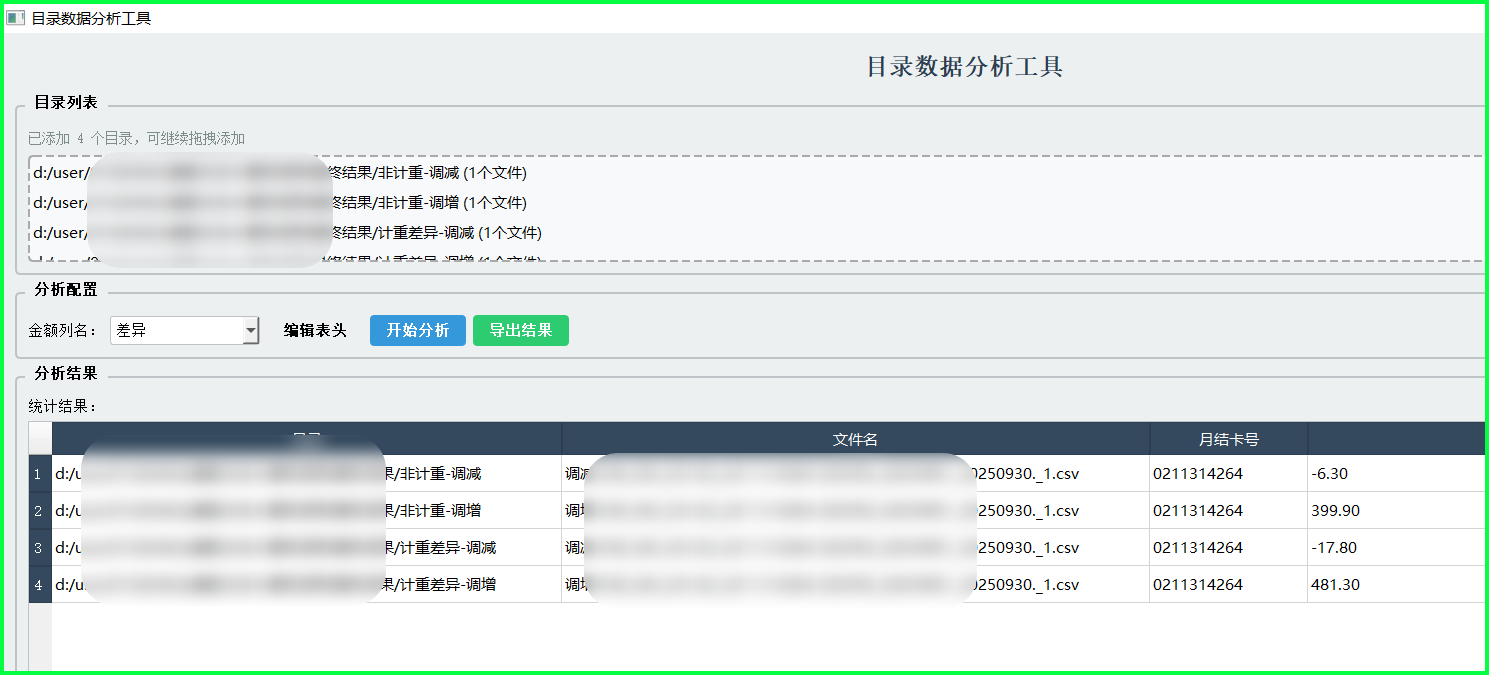
批量处理 Excel/CSV 数据的透视利器:基于 Python 和 PyQt5 的目录数据分析工具
在日常的数据处理工作中,我们经常会遇到需要处理大量分散在不同文件夹中的 Excel 或 CSV 文件的情况。如果手动打开每个文件去统计数据,不仅效率低下,而且容易出错。本文将介绍一个使用 Python 编写的桌面应用程序,它结合了 PyQt5 的图形界面和 Pandas 的强大数据处理能力,能够轻松实现多目录数据的批量读取、清洗、汇总和导出。
完整代码以及打包工具请点击Github链接:csv&Excel批量透视某一列(数值格式)
完整代码以及打包工具请点击Github链接:csv&Excel批量透视某一列(数值格式)
完整代码以及打包工具请点击Github链接:csv&Excel批量透视某一列(数值格式)
🔍 工具概览
这个工具的主要功能包括:
- 拖拽式操作:支持直接将文件夹拖拽到软件界面中,自动识别其中的
.xlsx和.csv文件。 - 智能表头识别:自动读取第一个文件的表头供用户选择“金额”列(或其他数值列)。
- 表头编辑功能:如果文件表头不规范,支持手动编辑映射,确保数据读取准确。
- 数据自动清洗:自动剔除原文件中包含“合计”字样的行和列,避免重复计算。
- 多线程处理:使用独立线程进行文件读取和计算,确保界面操作流畅,不会出现卡顿。
- 实时进度反馈:在分析过程中实时显示正在处理的文件路径。
- 结果导出:支持将分析结果(目录、文件名、金额汇总)导出为新的 Excel 文件。
🛠️ 技术栈
- Python 3:核心编程语言。
- PyQt5:用于构建现代化的桌面 GUI 界面。
- Pandas:用于高效的数据读取(read_excel/read_csv)和数据处理(DataFrame)。
- Openpyxl:Pandas 读取 Excel 文件的依赖库。
- Pathlib:用于优雅地处理文件路径。
💻 核心代码解析
1. 支持拖拽的列表控件 (FileDropWidget)
为了提供更好的用户体验,我们继承了 QListWidget 并重写了拖拽相关的事件方法,使其支持文件夹的拖拽输入。
class FileDropWidget(QListWidget):
directories_dropped = pyqtSignal(list)
def __init__(self, parent=None):
super().__init__(parent)
self.setAcceptDrops(True) # 开启拖放支持
# ... 样式设置 ...
def dragEnterEvent(self, event):
# 当拖入的是文件/文件夹路径时接受
if event.mimeData().hasUrls():
event.accept()
else:
event.ignore()
def dropEvent(self, event):
directories = []
for url in event.mimeData().urls():
path = url.toLocalFile()
if os.path.isdir(path):
directories.append(path)
if directories:
self.directories_dropped.emit(directories) # 发送信号
event.accept()
2. 后台分析线程 (AnalysisWorker)
数据分析是一个耗时操作,如果直接在主线程执行会导致界面假死。因此,我们使用 QThread 创建一个工作线程来处理核心逻辑。
在这个线程中,我们遍历所有目录,读取文件,并进行关键的数据清洗操作:
class AnalysisWorker(QThread):
# 定义信号用于更新界面
progress_updated = pyqtSignal(str)
file_result_ready = pyqtSignal(dict)
finished_analysis = pyqtSignal(dict)
def _preprocess_df(self, df):
"""预处理DataFrame,移除合计列和行"""
# 移除名为"合 计"或"合计"的列
cols_to_drop = [c for c in df.columns if str(c).strip() in ['合 计', '合计']]
if cols_to_drop:
df = df.drop(columns=cols_to_drop)
# 移除包含"合 计"或"合计"的行
for col in df.columns:
if df[col].dtype == 'object':
mask = df[col].astype(str).str.contains('合 计|合计', regex=True, na=False)
df = df[~mask]
return df
def run(self):
# ... 遍历目录和文件 ...
try:
# 读取 Excel 或 CSV
df = pd.read_excel(excel_file, header=0)
# 数据清洗
df = self._preprocess_df(df)
# 统计指定列的总和
if self.amount_column in df.columns:
df[self.amount_column] = pd.to_numeric(df[self.amount_column], errors='coerce')
file_total = df[self.amount_column].sum()
# 发送结果
self.file_result_ready.emit({...})
except Exception as e:
print(f"读取文件失败: {e}")
3. 主窗口逻辑 (MainWindow)
主窗口负责将各个组件组装起来,并处理用户交互。它包括了目录列表、配置区域(选择金额列)、结果展示表格以及控制按钮。
特别值得一提的是,在添加目录后,程序会自动扫描第一个文件以获取表头信息,填充到下拉框中供用户选择:
def scan_first_file_headers(self):
"""扫描第一个文件的表头"""
for directory in self.directories:
# 查找第一个Excel或CSV文件
for ext in ['*.xlsx', '*.csv']:
files = list(Path(directory).glob(ext))
if files:
# 读取第一行获取表头
# ...
self.amount_combo.clear()
for header in df.columns:
# 过滤掉合计列
if str(header).strip() not in ['合 计', '合计']:
self.amount_combo.addItem(header)
return
🚀 如何使用
- 启动程序:运行脚本后,会显示“目录数据分析工具”的主界面。
- 添加目录:将包含数据文件的文件夹直接拖入程序上方的虚线框区域。
- 配置参数:
- 程序会自动识别表头,请在“金额列名”下拉框中选择你需要统计的列。
- 如果表头识别有误,可以点击“编辑表头”进行手动调整。
- 开始分析:点击“开始分析”按钮,程序将自动遍历所有文件并计算总和。
- 查看结果:分析过程中,下方表格会实时显示每个文件的统计结果,底部显示总计金额。
- 导出数据:点击“导出结果”按钮,可以将当前的统计明细保存为 Excel 文件。
📝 总结
通过 Python 结合 PyQt5 和 Pandas,我们用几百行代码就实现了一个功能完善、界面友好的批量数据处理工具。它展示了 Python 在办公自动化领域的强大潜力——不仅能处理数据,还能封装成易用的桌面软件,极大提升工作效率。
如果你也有类似的数据处理需求,不妨参考这个思路,定制属于你自己的数据分析工具!