

告别 VLOOKUP 卡顿!Python 开发通用 Excel/CSV 匹配神器
在日常办公数据处理中,我们经常面临这样的场景:需要从一个巨大的总表(Master Data)中,根据某些字段(如订单号、身份证号)查找对应的信息并填充到另一张表中。
通常我们会使用 Excel 的 VLOOKUP 或 XLOOKUP 公式。但在面对几十万行数据,或者需要跨多个文件批量匹配时,Excel 往往会变得卡顿甚至崩溃。此外,当匹配条件复杂(例如需要组合“姓名+手机号”作为唯一键)时,公式的编写也容易出错。
今天为大家介绍一套基于 Python + PyQt5 开发的通用 Excel/CSV 匹配工具。它将匹配过程拆分为“建库”和“匹配”两个步骤,利用 Hash Map (字典) 实现极速匹配,彻底解决大文件处理难题。
核心设计思路
本工具套件包含两个独立应用,采用了“以空间换时间”的策略:
-
数据源转换器 (
excel&csv_2_json.py):
负责读取原始数据源(Excel/CSV),用户可以灵活定义唯一键(Key)和取值列(Value)。程序将这些数据清洗并转换为结构化的 JSON 文件(即 Python 字典格式)。- 技术优势:JSON 字典的查找时间复杂度为 O(1),远快于 Excel 的线性查找。
-
数据匹配器 (
march.py):
负责读取待匹配的文件,根据用户指定的列生成查找键,在 JSON 字典中瞬间找到对应值,并追加到表格末尾。- 技术优势:支持批量处理文件夹下的所有文件,一次性完成所有匹配工作。
Github源代码:csv文件通用匹配工具
Github源代码:csv文件通用匹配工具
Github源代码:csv文件通用匹配工具
工具亮点
1. 极速读取,告别等待
底层使用了基于 Rust 开发的 python-calamine 库来读取 Excel 文件。相比传统的 openpyxl 或 pandas,它在读取大型 .xlsx 文件时速度有着数量级的提升,且内存占用更低。
2. 灵活的“组合键”支持
很多时候单列数据不足以唯一标识一条记录。
- 传统做法:在 Excel 中插入辅助列,用
A2&B2拼接字符串。 - 本工具做法:在界面上直接勾选多个列(如“部门”和“姓名”),程序自动在后台拼接成
部门|姓名的唯一键。匹配时只需在另一个文件中勾选对应含义的列即可。
3. 智能的“停止词”截断
处理财务报表或系统导出数据时,往往文件底部会有“合计”、“制表人”等非数据行。
工具内置“停止词”功能(默认为“合 计”)。读取数据时,一旦某行包含该词,程序会自动停止读取后续内容,确保生成的字典纯净无脏数据。
使用教程
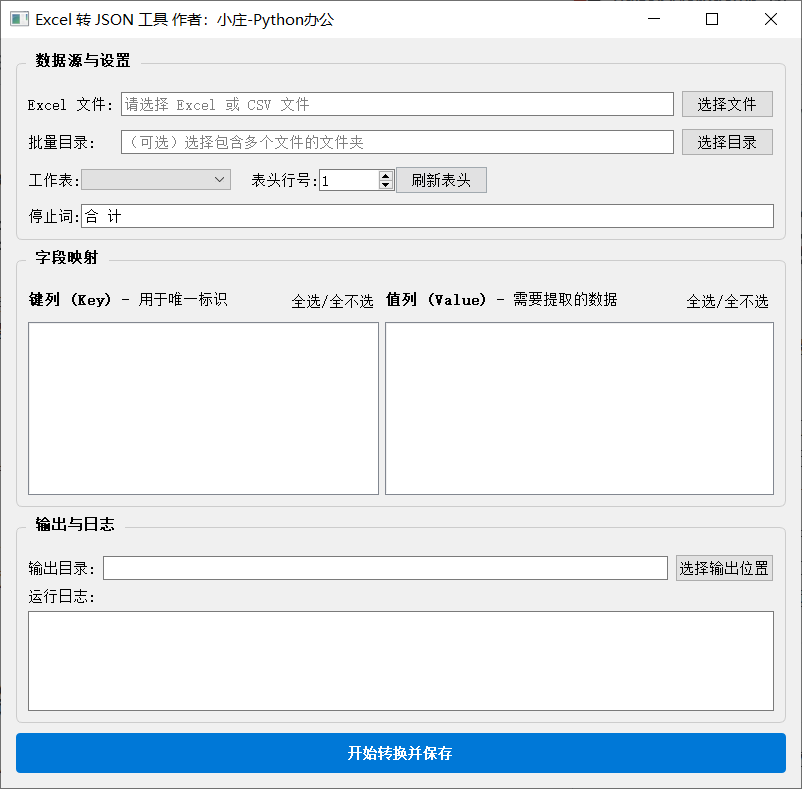
第一阶段:制作数据字典
启动 excel&csv_2_json.py。
- 导入数据:选择你的总表 Excel 或包含多个分表的文件夹。
- 设定表头:如果第一行不是标题,可以调整“表头行号”并刷新。
- 定义规则:
- 左侧列表:勾选作为 Key 的列(如
SKU编码)。 - 右侧列表:勾选需要提取的数据列(如
商品名称、单价)。
- 左侧列表:勾选作为 Key 的列(如
- 生成:点击转换,你将得到一个
data_march.json文件。
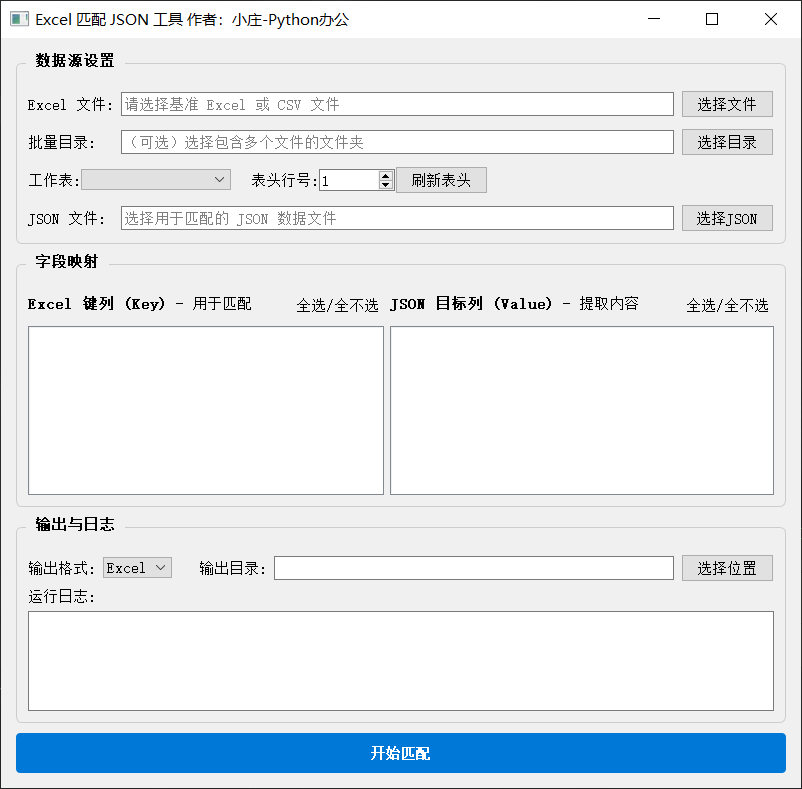
第二阶段:批量匹配
启动 march.py。
- 准备工作:选择你需要填充数据的 Excel 文件(支持批量目录)。
- 加载字典:导入上一步生成的 JSON 文件。
- 关联映射:
- 在“Excel 键列”中勾选对应的列(如
SKU编码,顺序需与第一阶段一致)。 - 在“JSON 目标列”中勾选你想把哪些数据填入表中。
- 在“Excel 键列”中勾选对应的列(如
- 输出结果:点击开始匹配,工具会生成新的文件,将匹配到的数据自动追加在右侧。
为什么选择 Python 自研工具?
对于开发者而言,这个项目展示了 PyQt5 构建桌面应用的典型范式:
- 界面与逻辑分离:通过信号与槽机制处理交互。
- 配置化思维:不把列名写死在代码里,而是让用户动态从文件中读取并选择。
- 异常处理:针对 CSV 的编码问题(UTF-8-SIG vs GBK)做了自动探测兼容。
对于非技术用户,这是一个开箱即用的高效工具,无需安装庞大的数据分析环境,无需编写复杂的 Python 脚本,即可享受编程带来的效率红利。
获取与运行
项目开源代码已发布,你需要安装以下依赖即可运行:
pip install PyQt5 python-calamine openpyxl
快来尝试一下,把原本需要一下午的 VLOOKUP 工作缩短到几分钟吧!
