

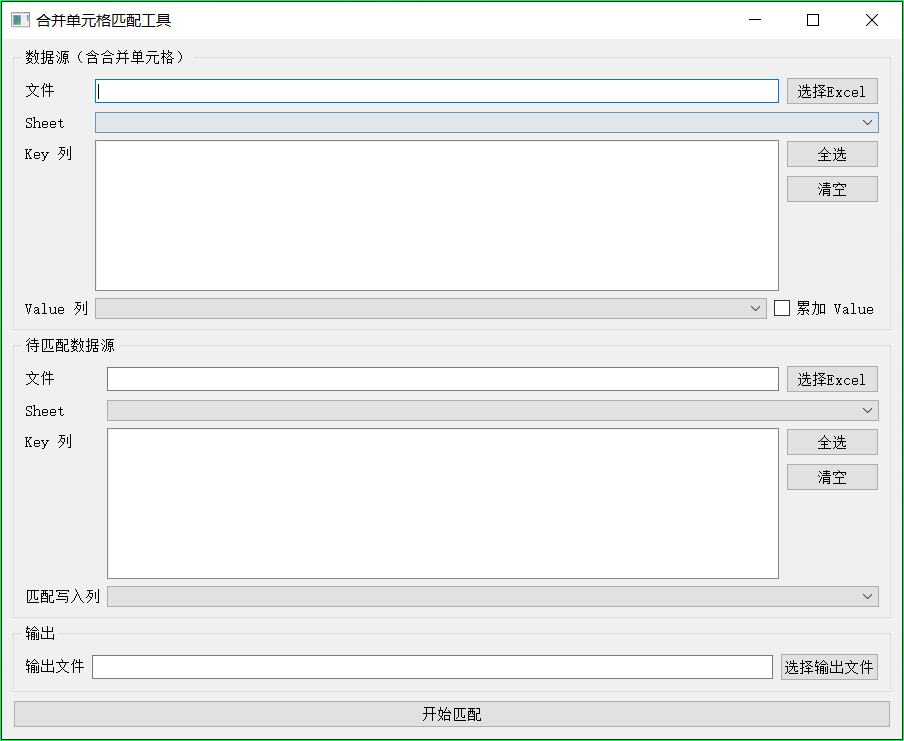
合并单元格匹配工具:从“合并单元格”到稳定的 Key→Value 映射
这篇文章记录一个在业务里非常常见、但在实现上很容易踩坑的需求:从带有合并单元格的 Excel 表中抽取 Key→Value 映射,再把匹配结果写回到另一个 Excel 表中。项目以 PyQt5 提供界面(exe 可打包发布),核心匹配逻辑基于 openpyxl 实现。
本文不包含任何本地路径或 IDE 跳转链接,方便直接复制到任意博客平台。仓库入口说明见 README.md,核心逻辑主要在 excel_merge_match.py。
1. 业务痛点:合并单元格导致“读出来是空”
在 Excel 中,合并单元格的值只会存储在合并区域左上角“锚点”单元格里;区域内其他单元格的值通常是 None。这会带来一个直接问题:
- 你看到表格视觉上某列每行都有值
- 但程序逐行读取时,某些行的 key 列读取出来是空,于是匹配 key 断裂、映射丢失
因此,“正确处理合并单元格”是这个工具的核心能力之一。
2. 总体方案:两阶段处理
整个流程分成两步:
- 从“数据源 Excel”构建映射
mapping: Dict[str, Union[str, int, float]] - 遍历“匹配源 Excel”,按 key 查表,把 value 写入指定列(或新增列)
对应实现主要是两个函数(都在 excel_merge_match.py):
build_source_mapping(src_cfg):从“数据源 Excel”构建 key→value 映射apply_mapping_to_target(...):把映射写回到“匹配源 Excel”,并输出新文件
为了让逻辑清晰可测,配置以两个不可变 dataclass 表达:
SourceConfig:数据源配置(文件、sheet、key 列、value 列、是否累加)TargetConfig:目标表配置(文件、sheet、key 列、写入列)
3. 表头与列选择:用“列名”而不是“列号”
在业务数据里,用户往往只知道“列名是什么”,而不是 A/B/C 或具体列号。这里采取的策略是:
- 默认用第一行作为表头
- 如果表头为空,则自动命名为
列{idx}(例如 列1、列2) - 以“列名→列号”字典做解析
相关实现函数(都在 excel_merge_match.py):
_header_to_col(ws):从第一行生成“列名→列号”的映射_resolve_column(header_to_col, col_name)/_resolve_columns(...):按列名解析列号(找不到就抛错)
列枚举能力用于 UI 端的下拉框/多选框:
list_sheets(xlsx_path):列出所有 sheetlist_columns(xlsx_path, sheet_name):列出第一行的列名(空表头会补成列{idx})
4. 合并单元格展开:构建“坐标→锚点”查找表
核心思路是先扫描工作表的所有合并区域,构建一个 lookup:
- key:任意单元格坐标
(row, col) - value:该单元格所在合并区域的锚点坐标
(min_row, min_col)
实现函数:_build_merged_lookup(ws)
然后读取单元格值时遵循:
- 如果当前单元格本身有值,直接返回
- 如果当前单元格为空,且存在合并锚点,则回退到锚点读取
- 其他情况返回
None
实现函数:_get_cell_value(ws, merged_lookup, row, col)
这样就实现了“视觉上每行都有值”的效果:合并区域中的每行都能读到同样的 key。
5. Key 的构建:多列拼接 + 规范化
Key 支持多列组成,拼接规则是用 _ 连接:
key = "_".join([k1, k2, k3])
关键点有两个:
5.1 文本规范化
所有 key 部分会被转成字符串并 strip(),避免因为尾部空格导致匹配失败。实现函数:_normalize_text(v)。
5.2 过滤“缺失 key”的行
任意一列 key 为空,就认为 key 不完整,跳过该行(避免生成脏 key)。这个规则在构建映射(build_source_mapping)与写回匹配(apply_mapping_to_target)两处都生效。
6. Value 的处理:支持“累加”模式
Value 的规范化规则是:
None视为无效值,跳过- 数字(int/float)保留数值类型
- bool 转成字符串(避免与数值逻辑混淆)
- 其他类型按字符串
strip(),空串视为无效值
实现函数:_normalize_value(v)
6.1 非累加模式:后写覆盖
当 accumulate=False 时,同一 key 发生重复,后面的值会覆盖前面的值(见 build_source_mapping 的主循环)。
6.2 累加模式:数值求和 / 文本拼接去重
当 accumulate=True 时:
- 如果 old/new 都是数值:求和(int+int 仍为 int,否则转 float)
- 其他情况:用
;拼接,并按分号拆分后做去重
实现函数:_accumulate(old, new)
以及分号拆分器:_split_parts(s)
这与 README 的规则描述一致(数值求和 / 非数值用 ; 拼接并去重)。
7. 写回策略:写到已有列或新增列
写回时支持两种模式:
- 用户指定写入列名:写到该列(列必须存在,否则抛 KeyError)
- 用户不指定写入列:自动新增到最后一列,并写入表头
对应实现函数:apply_mapping_to_target(...)
表头命名规则:
- 优先使用
output_header - 为空则使用
匹配_{Value列名}(Value 列名来自src_cfg.value_column)
另外,为了方便输出到任意目录,保存前会确保输出目录存在(逻辑同样位于 apply_mapping_to_target 内)。
8. 一个最小“脚本化”调用示例
GUI 通常会把用户选项转成配置对象,然后调用这两个函数。下面给出一个纯脚本方式的例子(仅用于理解调用形态):
from excel_merge_match import (
SourceConfig,
TargetConfig,
apply_mapping_to_target,
build_source_mapping,
)
src_cfg = SourceConfig(
xlsx_path="source.xlsx",
sheet_name="Sheet1",
key_columns=("物料编码", "批号"),
value_column="数量",
accumulate=True,
)
mapping = build_source_mapping(src_cfg)
tgt_cfg = TargetConfig(
xlsx_path="target.xlsx",
sheet_name="Sheet1",
key_columns=("物料编码", "批号"),
write_to_column=None,
)
matched, total = apply_mapping_to_target(
src_cfg=src_cfg,
mapping=mapping,
tgt_cfg=tgt_cfg,
output_path="target_out.xlsx",
output_header="匹配数量",
)
print(matched, total)
9. 边界情况与注意事项
- 表头重复:当前策略是“同名列只取第一次出现的位置”(避免歧义),由
_header_to_col保证 - Key 拼接冲突:使用
_拼接时,如果 key 列本身包含_,理论上可能造成不同组合得到同一字符串;如果在你的数据里会发生,建议在 UI 里提供“分隔符”可配置或使用不可见分隔符。 - 大文件性能:
_build_merged_lookup会为每个合并区域内每个格子建立映射,合并区域特别大时可能占用较多内存;但这换来了读取阶段非常简单的 O(1) 回退查找。 - openpyxl 的
data_only=True:意味着读取到的是“公式计算后的值”(如果文件中有缓存结果);如果源文件公式未计算过,可能会读到None。这属于 openpyxl 的常见特性。
10. 依赖与打包简述
依赖见 requirements.txt:
- PyQt5:界面与交互
- openpyxl:Excel 读写与合并单元格处理
Windows 打包产物与说明见 README 的“最小化打包(Windows)”章节。