

我用 Python 做了一个公众号文章提取器,还顺手配了个桌面界面
很多人做内容整理,卡的不是“不会保存”,而是“保存太麻烦”。
尤其是公众号文章。你在群里、朋友圈、收藏夹里看到一堆文章,想把它们统一整理下来,常见做法通常很原始:打开文章,复制,粘贴,改标题,再保存。重复几次之后,人就烦了。
所以我做了一个小工具:公众号文章提取器。
它不是一个复杂的大项目,核心目标就一件事:把公众号文章链接批量提取出来,抓取正文,并保存为本地 TXT 文件。
更重要的是,我没有只做命令行版本,而是直接配了一个 PyQt5 图形界面。这样一来,不懂代码的人也能直接用。
工具下载地址
我用夸克网盘给你分享了「公众号文章提取器-代码版.zip」,点击链接或复制整段内容,打开「夸克网盘APP」即可获取。
/~97c53YkwPg~:/
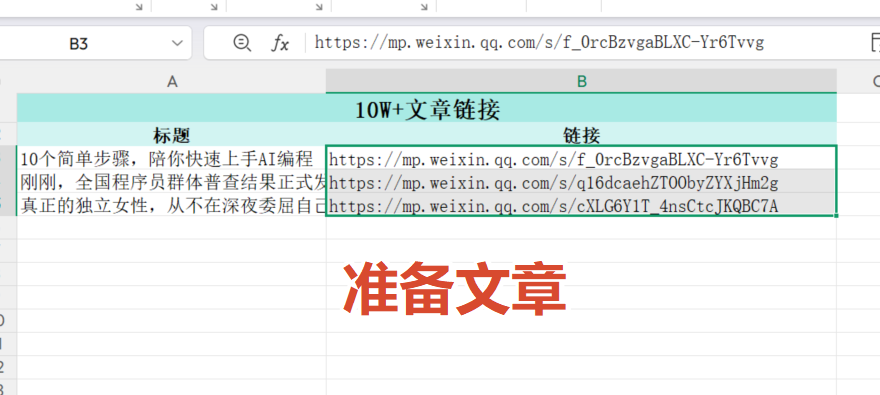
链接:https://pan.quark.cn/s/cf26ff76841a
这个工具到底解决什么问题
先说结论,这个项目解决的是“内容归档效率”问题。
现实场景很常见:
- 你在聊天记录里看到十几篇公众号文章
- 你想把这些内容统一存到本地
- 你不想一篇一篇手动复制
- 你还希望保存时带上标题、作者、发布时间和原文链接
这时候,一个能批量处理 URL、自动抓取正文、自动保存 TXT 的小工具,就很有价值。
它的定位很明确:
- 不追求平台级采集
- 不做复杂账号系统
- 不做云端存储
- 就专注把“单篇或多篇公众号文章整理到本地”这件事做好
这类工具最适合个人知识管理、资料备份、学习整理和选题归档。
我为什么选择 PyQt5 + requests + BeautifulSoup
这套组合很朴素,但非常实用。
requests 负责抓页面,足够轻,语义也清晰。对于一个文章提取器来说,先把页面拿下来,比什么都重要。
BeautifulSoup 负责解析 HTML。公众号文章虽然不是标准化 API 输出,但常见正文区域通常集中在几个固定节点里,比如:
#js_content.rich_media_contentarticle
有了这些经验位点,正文提取就不算太难。
至于 PyQt5,原因也很简单:我不想把这个工具做成“只有会敲命令的人才能用”的样子。
很多时候,真正影响工具传播的,不是核心逻辑,而是最后那一层交互。你给别人一个 python main.py,对方未必愿意用;你给别人一个清晰的桌面窗口,输入框、按钮、进度条、预览区都摆好,门槛立刻就降下来了。
所以这个项目虽然功能不大,但用户体验层面我还是认真做了。
这个项目是怎么工作的
整个流程并不复杂,大致分成 4 步。
第一步:从输入内容里识别 URL
用户可以直接贴链接,也可以贴一大段文字。
程序会用正则自动识别其中的 URL,并做去重处理。这个设计很实用,因为真实使用里,用户经常不是“准备好了标准链接列表”才来用工具,而是直接把聊天记录、备忘录、群消息整段粘过来。
工具应该适应用户,而不是让用户先适应工具。
第二步:逐篇抓取文章页面
程序会用一个带浏览器请求头的 requests.Session() 去访问页面,尽量模拟普通浏览器请求行为,减少一些基础层面的访问问题。
拿到页面 HTML 后,再进入解析流程。
第三步:提取文章核心信息
程序会尝试提取这些信息:
- 标题
- 作者
- 发布时间
- 正文内容
如果装了 beautifulsoup4,就优先走 DOM 解析逻辑;如果没有,也预留了一个正则兜底版本。
我很喜欢这种“主流程稳定,异常时有 fallback”的设计。因为真实环境里,代码不是只在你电脑上跑一次,它会面对不同机器、不同依赖状态、不同页面结构。留后路,通常不是多余,而是必要。
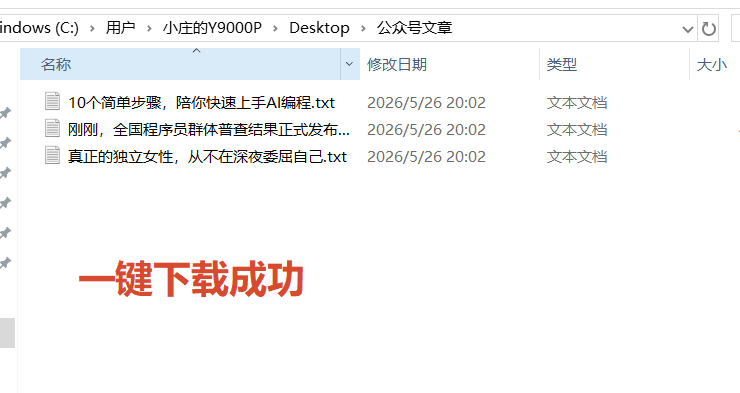
第四步:保存为本地 TXT
提取成功之后,程序会把内容保存成 TXT 文件,内容里会包含:
- 标题
- 作者
- 发布时间
- 原文链接
- 正文
文件名默认使用文章标题,如果重名会自动加后缀,避免覆盖已有文件。
这一步看起来普通,但对“长期归档”特别重要。因为只抓正文而不保留元信息,后面你再回头整理时,很容易忘记文章来源、发布时间和上下文。
图形界面做了哪些体验优化
这个项目不只是能跑,我还尽量把一些容易忽视的小细节补上了。
比如:
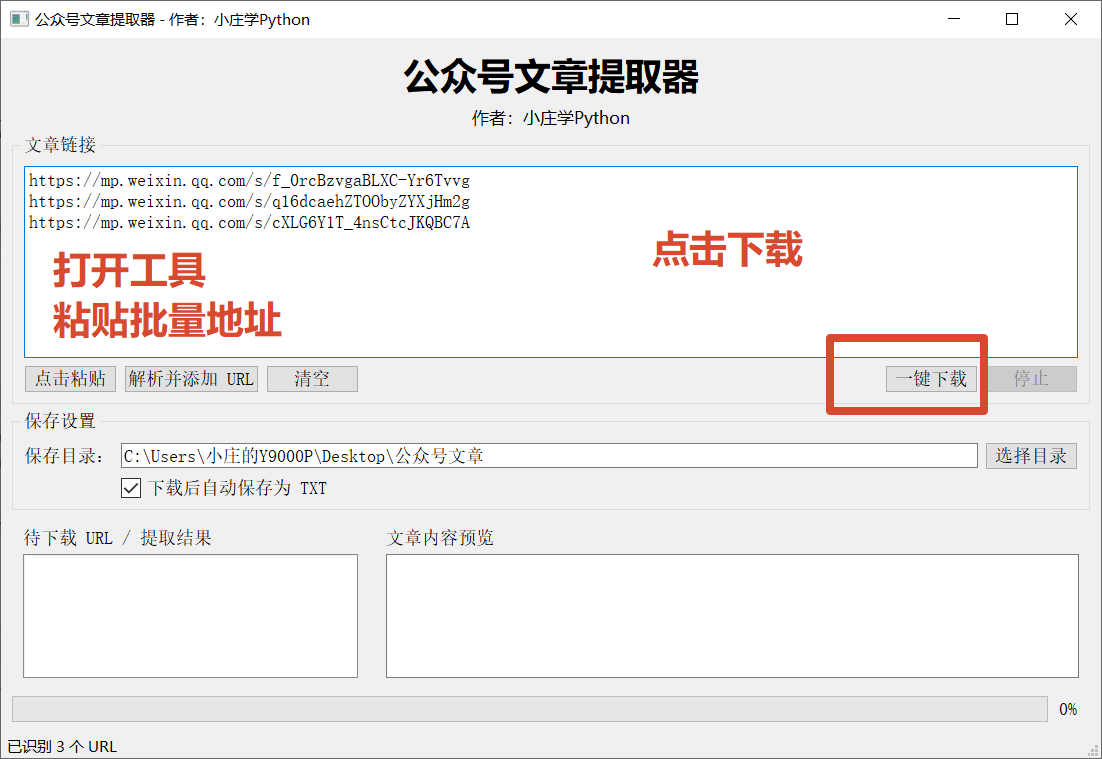
- 支持“点击粘贴”,直接读取剪贴板
- 输入框内容变化时,自动统计识别到多少个 URL
- 左侧列表显示提取结果,右侧实时预览文章内容
- 有进度条反馈当前任务状态
- 支持中途点击“停止”
- 支持自定义保存目录
这些功能单看都不大,但组合起来,就会让工具从“能用”变成“顺手”。
我一直觉得,小工具最怕的是作者只关注“功能有没有实现”,却忽略“用户有没有耐心用第二次”。如果第二次都不想打开,那这个工具其实还没做完。
这个项目最有价值的地方,不是爬取,而是整理
很多人看到这类项目,第一反应会放在“爬”这个动作上。
但我觉得它真正有价值的点,其实是“整理”。
抓取只是过程,整理才是结果。
当你把散落在不同对话、不同时间、不同入口里的公众号文章,统一转成结构化文本文件时,内容才真正进入你的个人知识库。之后你可以继续做分类、摘录、打标签,甚至再导入到自己的笔记系统里。
从这个角度看,这个项目其实更像一个“内容归档入口”,而不只是一个“网页提取脚本”。
这个工具也有边界
当然,这种工具不是万能的。
它有几个很现实的限制:
- 依赖目标页面当前结构,结构变化会影响提取结果
- 某些文章可能受访问策略影响,无法稳定抓取
- 当前版本主要保存为
TXT,格式能力还比较基础 - 没有做图片资源下载,也没有做更复杂的富文本还原
但这些限制并不意味着项目没价值。
恰恰相反,我越来越认同一种开发思路:先把一个高频、具体、真实的问题解决到 80 分,再考虑扩展。
比起一上来就做很大的系统,我更喜欢先做一个可以立刻带来效率提升的小工具。因为小工具的反馈最快,也最容易进入真实使用场景。
后面还能怎么升级
如果继续往下做,这个项目还有不少可以扩展的方向:
- 增加
Markdown导出 - 下载并保存文章图片
- 支持失败重试
- 支持并发抓取提升速度
- 增加分类归档能力
- 打包成可分发的
exe
如果再往前走一步,甚至可以做成“文章采集 + 内容清洗 + 本地知识库导入”的一整套工作流。
不过在现阶段,我反而觉得保持克制是对的。先把核心体验打磨好,比堆功能重要。
最后
这个 公众号文章提取器 本质上不是一个炫技项目。
它没有复杂架构,也没有花哨概念。它做的事情很朴素:帮你把分散的公众号文章更快地收集、提取、保存下来。
但越是这种朴素工具,越容易真正进入日常工作流。
很多时候,效率提升并不来自一个巨大的平台,而来自一个你愿意每天打开的小程序。
如果你也经常需要整理公众号文章,这类工具会很值得做。哪怕先从一个 main.py 开始,也完全够了。